
IMGT Repertoire (RPI)
Other CD4 entries
- Mus musculus: CD4
IMGT RPI entry from gene to protein for Homo sapiens CD4
Citing IMGT RPI entry for CD4
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens CD4
- IMGT gene definition: CD4 antigen (p55)
Chromosomal localization
- Chromosome: 12
- Chromosomal localization: 12pter-p12
Gene exon/intron organization
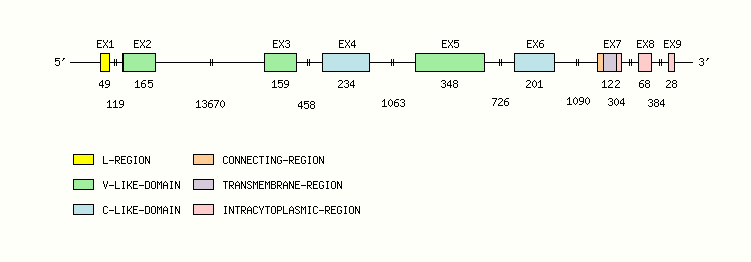
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 5
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| CD4*01 | F | EX1-9 | M12807 [1] | cDNA |
| CD4*02 | F | EX1-9 | M35160 [2] | cDNA (1) |
| CD4*03 | F | EX4-5 | U40625 [3] | cDNA partial (2) |
| CD4*04 | F | EX1-9 | DQ012936 | gDNA (3) |
| CD4*05 | F | EX1-9 | U47924 [4] | gDNA (4) |
IMGT reference sequences (in FASTA format) for the allele(s): CD4*01 to CD4*05
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| CD4*01 | F | EX1-2 | S79267 | cDNA partial |
| X87579 | cDNA partial | |||
| CD4*04 | F | EX1-9 | BC025782 | cDNA |
| BT019791 | cDNA | |||
| BT019811 | cDNA | |||
| CD4*05 | F | EX1-9 | NM_000616 | cDNA |
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| CD4*01 | M12807 | 458 aa | 1 | |
| CD4*02 | M35160 | 458 aa | 1 | |
| CD4*03 | U40625 | Tr:Q6LCP8 | 78 aa | 1 partial |
| CD4*04 | DQ012936 | 458 aa | 1 | |
| CD4*05 | U47924 | P11942 | 458 aa | 1 |
| NM_000616 | NP_000607 | 458 aa | 1 | |
IMGT notes:
- (1) In EX5 [D3] c199>t; R67>W numbering according to IMGT unique numbering for V-LIKE-DOMAIN. This mutation leads to OKT4-epitope deficiency.
- (2) Partial with only EX4 [D2]. c318>t.
- (3) In EX3 [D1] c261>t (c62>t), numbering according to IMGT unique numbering for V-LIKE-DOMAIN.
- (4) In EX3 [D1] c261>t (c62>t), and in EX5 [D3] c126>t numbering according to IMGT unique numbering for V-LIKE-DOMAIN and in EX8 c63>t.
IMGT references:
- [1] Maddon P.J, et al. Cell 42, 93-104 (1985). PMID:2990730
- [2] Hodge,T.W., Sasso,D.R. and McDougal,J.S. Hum. Immunol. 30, 99-104 (1991). PMID:1708753
- [3] Indraccolo. S, et al. Immunogenetics 44, 70-72 (1996). PMID:8613144
- [4] Ansari-Lari.M.A, et al. Genome Res. 6, 314-326 (1996). PMID:8723724
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
Nucleotide sequence
1 atgaaccggg gagtcccttt taggcacttg cttctggtgc tgcaactggc gctcctccca 61 gcagccactc agggaaagaa agtggtgctg ggcaaaaaag gggatacagt ggaactgacc 121 tgtacagctt cccagaagaa gagcatacaa ttccactgga aaaactccaa ccagataaag 181 attctgggaa atcagggctc cttcttaact aaaggtccat ccaagctgaa tgatcgcgct 241 gactcaagaa gaagcctttg ggaccaagga aacttccccc tgatcatcaa gaatcttaag 301 atagaagact cagatactta catctgtgaa gtggaggacc agaaggagga ggtgcaattg 361 ctagtgttcg gattgactgc caactctgac acccacctgc ttcaggggca gagcctgacc 421 ctgaccttgg agagcccccc tggtagtagc ccctcagtgc aatgtaggag tccaaggggt 481 aaaaacatac agggggggaa gaccctctcc gtgtctcagc tggagctcca ggatagtggc 541 acctggacat gcactgtctt gcagaaccag aagaaggtgg agttcaaaat agacatcgtg 601 gtgctagctt tccagaaggc ctccagcata gtctataaga aagaggggga acaggtggag 661 ttctccttcc cactcgcctt tacagttgaa aagctgacgg gcagtggcga gctgtggtgg 721 caggcggaga gggcttcctc ctccaagtct tggatcacct ttgacctgaa gaacaaggaa 781 gtgtctgtaa aacgggttac ccaggaccct aagctccaga tgggcaagaa gctcccgctc 841 cacctcaccc tgccccaggc cttgcctcag tatgctggct ctggaaacct caccctggcc 901 cttgaagcga aaacaggaaa gttgcatcag gaagtgaacc tggtggtgat gagagccact 961 cagctccaga aaaatttgac ctgtgaggtg tggggaccca cctcccctaa gctgatgctg 1021 agcttgaaac tggagaacaa ggaggcaaag gtctcgaagc gggagaaggc ggtgtgggtg 1081 ctgaaccctg aggcggggat gtggcagtgt ctgctgagtg actcgggaca ggtcctgctg 1141 gaatccaaca tcaaggttct gcccacatgg tccaccccgg tgcagccaat ggccctgatt 1201 gtgctggggg gcgtcgccgg cctcctgctt ttcattgggc taggcatctt cttctgtgtc 1261 aggtgccggc accgaaggcg ccaagcagag cggatgtctc agatcaagag actcctcagt 1321 gagaagaaga cctgccagtg ccctcaccgg tttcagaaga catgtagccc catttga
Nucleotide sequence in FASTA format (without gaps)
CD4*01
Amino acid sequence
1 MNRGVPFRHL LLVLQLALLP AATQGKKVVL GKKGDTVELT CTASQKKSIQ FHWKNSNQIK 61 ILGNQGSFLT KGPSKLNDRA DSRRSLWDQG NFPLIIKNLK IEDSDTYICE VEDQKEEVQL 121 LVFGLTANSD THLLQGQSLT LTLESPPGSS PSVQCRSPRG KNIQGGKTLS VSQLELQDSG 181 TWTCTVLQNQ KKVEFKIDIV VLAFQKASSI VYKKEGEQVE FSFPLAFTVE KLTGSGELWW 241 QAERASSSKS WITFDLKNKE VSVKRVTQDP KLQMGKKLPL HLTLPQALPQ YAGSGNLTLA 301 LEAKTGKLHQ EVNLVVMRAT QLQKNLTCEV WGPTSPKLML SLKLENKEAK VSKREKAVWV 361 LNPEAGMWQC LLSDSGQVLL ESNIKVLPTW STPVQPMALI VLGGVAGLLL FIGLGIFFCV 421 RCRHRRRQAE RMSQIKRLLS EKKTCQCPHR FQKTCSPI*
Amino acid sequence in FASTA format (without gap)
CD4*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN on one layer, V-LIKE-DOMAIN on two layer, C-LIKE-DOMAIN on one layer, C-LIKE-DOMAIN on two layer, V-LIKE-DOMAIN on one layer, V-LIKE-DOMAIN on two layer, C-LIKE-DOMAIN on one layer, C-LIKE-DOMAIN on two layer
IMGT databases
- IMGT/3Dstructure-DB: 1CDH, 1CDI, 1CDJ, 1CDU, 1CDY, 1G9M, 1G9N, 1GC1, 1JL4, 1OPN, 1OPT, 1OPW, 1Q68, 1RZJ, 1RZK, 1WBR, 1WIO, 1WIP, 1WIQ, 3CD4
External links
Nomenclature
- HGNC: 1678
Genome databases
- Entrez Gene: 920
- GENATLAS: 83
- GeneCards: GC12P006769
- GDB: 119767
- OMIM: 186940
Sequence databases
- EMBL: M12807, M35160, U40625, DQ012936, U47924, S79267, X87579, BC025782, BT019791, BT019811
- GenBank: M12807, M35160, U40625, DQ012936, U47924, S79267, X87579, BC025782, BT019791, BT019811
- DDBJ: M12807, M35160, U40625, DQ012936, U47924, S79267, X87579, BC025782, BT019791, BT019811
- Swiss-Prot: P11942
- TrEMBL: Q6LCP8
- NCBI: NM_000616, NP_000607
Structure database
Created: 23/05/2007
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2024 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT