
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens CEACAM1
Citing IMGT RPI entry for CEACAM1
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens CEACAM1
- IMGT gene definition: Carcinoembryonic antigen-related cell adhesion molecule 1
Chromosomal localization
- Chromosome: 19
- Chromosomal localization: 19q13.2
Gene exon/intron organization
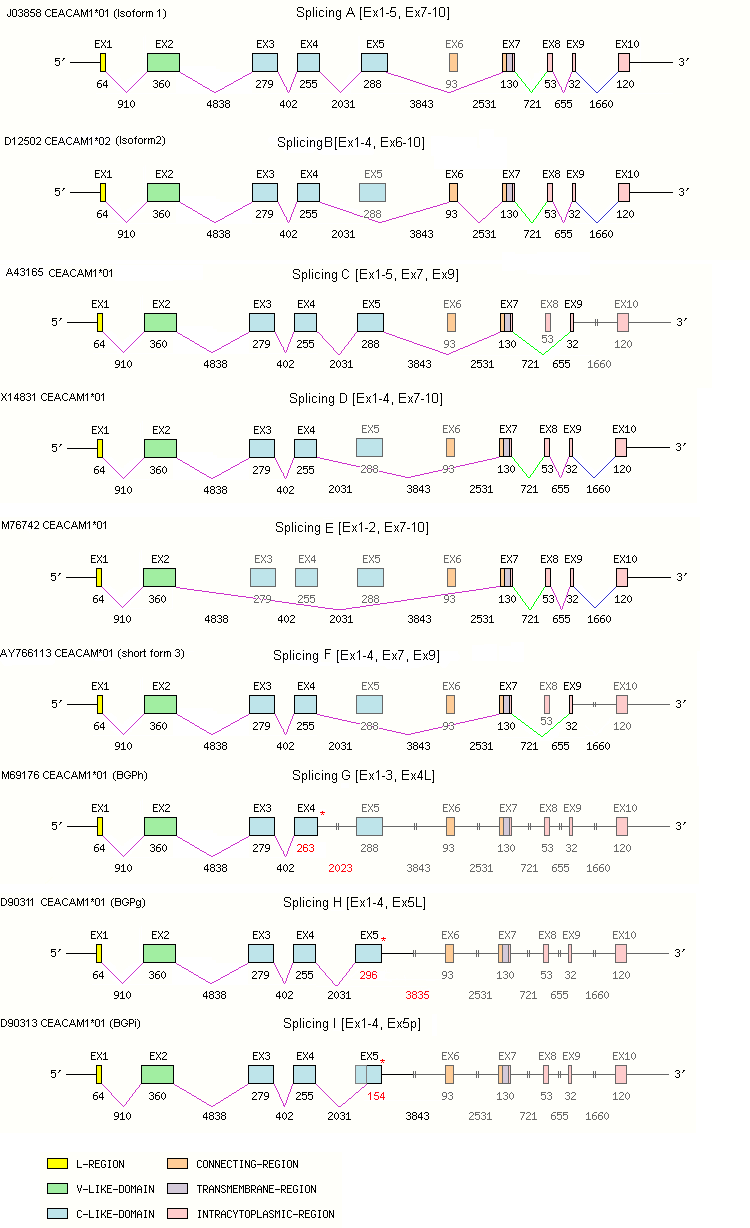
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 2
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| CEACAM1*01 | F | EX1-5, EX7-10 | AC004785 | gDNA |
| CEACAM1*02 | F | EX1-4, EX6-10 | D12502 [1] | cDNA (1) splicing B |
IMGT reference sequences (in FASTA format) for the allele(s): CEACAM1*01 to CEACAM1*02
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| CEACAM1*01 | F | EX1-5, EX7-10 | J03858 | cDNA |
| X16354 | cDNA | |||
| EX1-5, EX7, EX9 | A43165 | gDNA Splicing C | ||
| EX1-4, EX7-10 | X14831 | cDNA Splicing D | ||
| EX1-2, EX7-10 | M76742 | cDNA Splicing E | ||
| EX1-4, EX7, EX9 | AY766113 | cDNA Splicing F | ||
| EX1-3, EX4L | M69176 | cDNA Splicing G | ||
| EX1-4, EX5L | D90311 | cDNA Splicing H | ||
| EX1-4, EX5p | D90313 | cDNA Splicing I | ||
| EX1 | X67277 | gDNA | ||
| EX1-5, EX7-10 | NM_001712 | cDNA | ||
| EX1-5, EX7, EX9 | NM_001024912 | cDNA | ||
Corresponding protein database accession numbers
| Allele Name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| CEACAM1*01 | J03858 | P13688 | 526aa | 1 |
| NM_001712 | NP_001703 | 526aa | 1 | |
| NM_001024912 | NP_001020083 | 464aa | 2 | |
IMGT notes:
- (1) [EX4L and EX5L] represent the exons in which the usual DONOR-SPLICE is not used. As a consequence, the translation continues beyond this DONOR-SPLICE until the first STOP-CODON, in frame, in the downstream intron.
- (2) [EX5p] represents an exon which is partial in 5'.
- (3) Splicing C and F result from a premature STOP-CODON.
- (4) Splicing A and splicing B are named Isoform 1 and 2, respectively.
- (5) Splicing G, H and I are named BGPg, BGPh and BGPi, respectively.
- (6) In EX4 [D3] 28g>t; 10D>Y, positions according to IMGT unique numbering for C-DOMAIN and C-LIKE-DOMAIN and in EX8 43c>g.
IMGT references:
- [1] Hinoda Y. et al., Proc.Natl. Acad. Sci. USA. 85, 6959-6963 (1988). PMID:2457922
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
CEACAM1*01: AC004785(g)
Nucleotide sequence
1 atggggcacc tctcagcccc acttcacaga gtgcgtgtac cctggcaggg gcttctgctc 61 acagcctcac ttctaacctt ctggaacccg cccaccactg cccagctcac tactgaatcc 121 atgccattca atgttgcaga ggggaaggag gttcttctcc ttgtccacaa tctgccccag 181 caactttttg gctacagctg gtacaaaggg gaaagagtgg atggcaaccg tcaaattgta 241 ggatatgcaa taggaactca acaagctacc ccagggcccg caaacagcgg tcgagagaca 301 atatacccca atgcatccct gctgatccag aacgtcaccc agaatgacac aggattctac 361 accctacaag tcataaagtc agatcttgtg aatgaagaag caactggaca gttccatgta 421 tacccggagc tgcccaagcc ctccatctcc agcaacaact ccaaccctgt ggaggacaag 481 gatgctgtgg ccttcacctg tgaacctgag actcaggaca caacctacct gtggtggata 541 aacaatcaga gcctcccggt cagtcccagg ctgcagctgt ccaatggcaa caggaccctc 601 actctactca gtgtcacaag gaatgacaca ggaccctatg agtgtgaaat acagaaccca 661 gtgagtgcga accgcagtga cccagtcacc ttgaatgtca cctatggccc ggacaccccc 721 accatttccc cttcagacac ctattaccgt ccaggggcaa acctcagcct ctcctgctat 781 gcagcctcta acccacctgc acagtactcc tggcttatca atggaacatt ccagcaaagc 841 acacaagagc tctttatccc taacatcact gtgaataata gtggatccta tacctgccac 901 gccaataact cagtcactgg ctgcaacagg accacagtca agacgatcat agtcactgag 961 ctaagtccag tagtagcaaa gccccaaatc aaagccagca agaccacagt cacaggagat 1021 aaggactctg tgaacctgac ctgctccaca aatgacactg gaatctccat ccgttggttc 1081 ttcaaaaacc agagtctccc gtcctcggag aggatgaagc tgtcccaggg caacaccacc 1141 ctcagcataa accctgtcaa gagggaggat gctgggacgt attggtgtga ggtcttcaac 1201 ccaatcagta agaaccaaag cgaccccatc atgctgaacg taaactataa tgctctacca 1261 caagaaaatg gcctctcacc tggggccatt gctggcattg tgattggagt agtggccctg 1321 gttgctctga tagcagtagc cctggcatgt tttctgcatt tcgggaagac cggcagggca 1381 agcgaccagc gtgatctcac agagcacaaa ccctcagtct ccaaccacac tcaggaccac 1441 tccaatgacc cacctaacaa gatgaatgaa gttacttatt ctaccctgaa ctttgaagcc 1501 cagcaaccca cacaaccaac ttcagcctcc ccatccctaa cagccacaga aataatttat 1561 tcagaagtaa aaaagcagta a
Nucleotide sequence in FASTA format (without gaps)
CEACAM1*01
Amino acid sequence
1 MGHLSAPLHR VRVPWQGLLL TASLLTFWNP PTTAQLTTES MPFNVAEGKE VLLLVHNLPQ 61 QLFGYSWYKG ERVDGNRQIV GYAIGTQQAT PGPANSGRET IYPNASLLIQ NVTQNDTGFY 121 TLQVIKSDLV NEEATGQFHV YPELPKPSIS SNNSNPVEDK DAVAFTCEPE TQDTTYLWWI 181 NNQSLPVSPR LQLSNGNRTL TLLSVTRNDT GPYECEIQNP VSANRSDPVT LNVTYGPDTP 241 TISPSDTYYR PGANLSLSCY AASNPPAQYS WLINGTFQQS TQELFIPNIT VNNSGSYTCH 301 ANNSVTGCNR TTVKTIIVTE LSPVVAKPQI KASKTTVTGD KDSVNLTCST NDTGISIRWF 361 FKNQSLPSSE RMKLSQGNTT LSINPVKRED AGTYWCEVFN PISKNQSDPI MLNVNYNALP 421 QENGLSPGAI AGIVIGVVAL VALIAVALAC FLHFGKTGRA SDQRDLTEHK PSVSNHTQDH 481 SNDPPNKMNE VTYSTLNFEA QQPTQPTSAS PSLTATEIIY SEVKKQ*
Amino acid sequence in FASTA format (without gap)
CEACAM1*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN on one layer, V-LIKE-DOMAIN on two layers
IMGT databases
- IMGT/3Dstructure-DB: 1l6z
External links
Nomenclature
- HGNC: 1814
Genome databases
- Entrez Gene: 634
- GENATLAS: 543
- GeneCards: GC19M047703
- GDB: 127992
- OMIM: 109770
Sequence database
- EMBL: AC004785, J03858, X16354, M69176, D90312, D90311, D90313, M76742, X14831, AY766113, D12502, A43165, X67277
- GenBank: AC004785, J03858, X16354, M69176, D90312, D90311, D90313, M76742, X14831, AY766113, D12502, A43165, X67277
- DDBJ: AC004785, J03858, X16354, M69176, D90312, D90311, D90313, M76742, X14831, AY766113, D12502, A43165, X67277
- Swiss-Prot: P13688
- TrEMBL:
- NCBI: NM_001712, NP_001703, NM_001024912, NP_001020083
Structure database
- PDB: 1l6z
Created: 27/07/2006
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Stéphanie Douvres, Phani Vijay Garapati, Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Stéphanie Douvres, Phani Vijay Garapati, Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2024 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT