
IMGT Repertoire (RPI)
Other DSCAM entries
- Drosophila melanogaster: DSCAM
IMGT RPI entry from gene to protein for Homo sapiens DSCAM
Citing IMGT RPI entry for DSCAM
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens DSCAM
- IMGT gene definition: Down syndrome cell adhesion molecule
Chromosomal localization
- Chromosome: 21
- Chromosomal localization: 21q22.2
Gene exon/intron organization
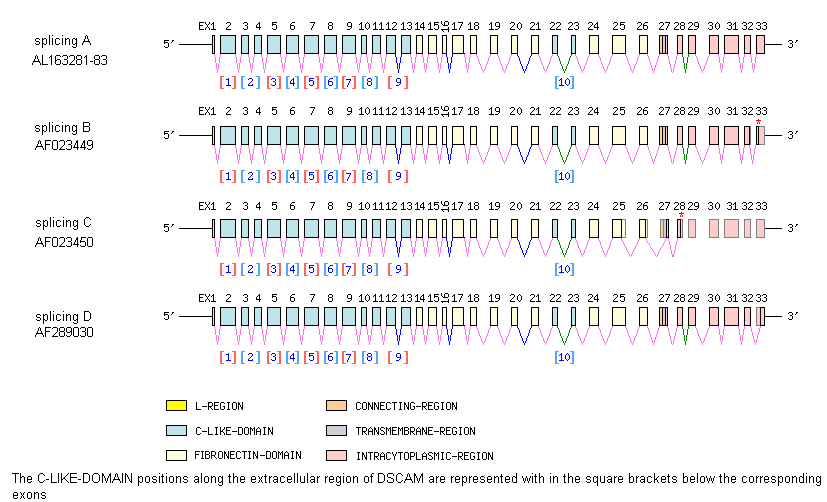
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 2
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | |||
|---|---|---|---|---|---|
| Clone names | Exons | Accession numbers | Molecule type | ||
| DSCAM*01 | F | EX1-3 | AL163283 | gDNA | |
| EX4-15 | AL163282 | ||||
| EX16-33 | AL163281 | ||||
| DSCAM*02 | F | EX1-33 | AB209136 | cDNA (1) | |
IMGT reference sequences (in FASTA format) for the allele(s): DSCAM*01 to DSCAM*02
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | |||
|---|---|---|---|---|---|
| Clone names | Exons | Accession numbers | Molecule type | ||
| DSCAM*01 | F | EX1-33 | AF217525 | cDNA | |
| EX2-33 | AF023449 | partial cDNA (2) splicing B | |||
| EX1-28 | AF023450 | cDNA (3) splicing C | |||
| EX5-33 | AF289030 | partial cDNA splicing D | |||
| EX1-33 | NM_001389 | partial cDNA | |||
| EX1-28 | NM_206887 | cDNA splicing C | |||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| DSCAM*01 | AL163283 | O60469 | 2012 aa | 1 |
| AF023449 | 1896 aa | 2 | ||
| AF023450 | O60469 | 1571 aa | 3 | |
| AF289030 | Q8WY19 | 1746 aa | 4 | |
| NM_001380 | NP_001380 | 2012 aa | 1 | |
| NM_206887 | NP_996770 | 1571 aa | 2 | |
| DSCAM*02 | AB209136 | Q59GH3 | 2012 aa | 1 |
IMGT notes:
- (1) 23c>g (8D>E) in [D3] domain of EX5.
- (2) 1896 aa. EX1 missing. In EX32 one nucleotide 'c' at position 294 is missing and this lead to the frame shift and pretermination of the protein.
- (3) 1571 aa. Multiple alternative splicing in EX25-27 leading to pre-termination of protein.
- (4) 1746 aa. Alternative splicing 54 bp from 5' site in EX33.
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
DSCAM*01: AL163283(g) AL163282(g) AL163281(g)
Nucleotide sequence
1 atgtggatac tggctctctc cttgttccag agcttcgcga atgttttcag tgaagaccta 61 cactccagcc tctactttgt caatgcatct ctgcaagagg tagtgtttgc cagcaccacg 121 gggactctgg tgccctgccc cgcagcaggc atccctcctg tgactctcag atggtaccta 181 gccacgggcg aggagatcta cgatgtcccc gggatccgcc acgtccaccc caacggcact 241 ctccaaattt tccccttccc tccttcaagc ttcagtacct taatccatga taatacttat 301 tattgcacag ctgaaaatcc ttcagggaaa attagaagtc aggatgtcca catcaaggct 361 gttttacggg agccctatac agtccgtgtg gaggaccaga aaaccatgag aggcaatgtt 421 gcggtcttca agtgcattat cccctcctcg gtggaggcgt acatcactgt cgtctcatgg 481 gagaaagaca ctgtttcact tgtctcagga tctagatttc tcatcacatc cacgggagcc 541 ttgtatatta aagatgtaca gaatgaagat ggattgtata actaccgctg catcacgcgg 601 catcgataca ccggagagac gaggcagagc aacagcgcca gactttttgt atcagaccca 661 gcgaactcag ccccatccat actggatggg tttgaccatc gcaaagccat ggctgggcag 721 cgtgtggagc tgccttgcaa agcgctcggg caccctgagc cagattaccg ctggctgaag 781 gacaacatgc ccctggaact ttcagggagg ttccagaaga ccgtgacggg gctgctcatt 841 gagaacattc gcccctcgga ctcaggcagc tatgtttgtg aagtgtccaa cagatacgga 901 actgctaagg tgataggccg cctgtacgtg aaacagccac tgaaagccac catcagtccc 961 aggaaggtta aaagcagcgt gggtagccaa gtttccttgt cctgcagcgt gacaggaact 1021 gaggaccagg aactctcctg gtaccgcaat ggtgaaatcc tcaaccctgg aaaaaatgtg 1081 aggatcacag ggatcaacca cgaaaacctt ataatggatc acatggtcaa aagtgacggg 1141 ggcgcatacc agtgctttgt gcgcaaggac aagctgtccg ctcaagacta tgtgcaggtg 1201 gtccttgaag atggaactcc caaaattatt tctgccttta gtgaaaaggt ggtgagtcca 1261 gcagagccgg tttcccttat gtgcaacgtg aagggaacac ctttgcccac gatcacgtgg 1321 accctggacg atgacccgat tctcaagggt ggcagtcacc gcatcagcca gatgatcacg 1381 tcggagggga acgtggtcag ctacctgaac atctccagct cccaggtccg ggacggggga 1441 gtctaccgct gcactgccaa caactcggcg ggagtcgtcc tgtaccaggc tcgaataaac 1501 gtaagagggc ctgcaagcat tcgaccaatg aaaaacatca cagcaatagc aggacgggac 1561 acatacattc actgtcgtgt gattggctat ccgtattact ccattaaatg gtacaagaac 1621 tctaacctgc ttcctttcaa ccaccgccaa gtggcatttg agaacaatgg aactcttaaa 1681 ctttcagatg tgcaaaagga agtggacgag ggggagtaca cgtgcaacgt gttggttcaa 1741 ccacaactct ccaccagcca gagcgtccac gtgaccgtga aagttccgcc tttcatacaa 1801 ccctttgagt ttccaagatt ctccattggg cagcgggtct tcatcccctg tgttgtggtc 1861 tcaggggact tacccatcac gatcacctgg cagaaggatg gccggccaat ccctgggagc 1921 cttggggtga ccattgacaa tattgacttc acgagctcct tgaggatttc caatctctcg 1981 ctcatgcaca atgggaatta cacctgcata gcccggaatg aggccgccgc tgtggagcac 2041 caaagccagt tgattgtcag agttcctccc aagtttgtgg ttcagccacg ggaccaggac 2101 gggatttatg gcaaagcagt catcctcaat tgttctgctg agggttaccc tgtacctacc 2161 atcgtgtgga aattctctaa aggtgctggg gttccccagt tccagccaat tgccctaaat 2221 ggccgaatcc aagttctcag caatgggtcg ttgctgatca agcatgtcgt ggaggaagac 2281 agtggctact acctctgcaa ggtcagcaac gatgtgggcg cagacgtcag caagtccatg 2341 tacctcacgg ttaaaattcc tgcgatgata acatcctatc caaatactac cctggccacg 2401 caggggcaga aaaaggagat gagctgcacg gcgcatggtg agaagcccat tatagtccgc 2461 tgggagaagg aggaccgaat cattaaccct gagatggccc gttatcttgt gtccaccaag 2521 gaggtgggag aagaggtgat ttctactctg cagattttgc caactgtgag agaagattct 2581 ggtttctttt cctgccatgc tattaattct tatggggagg accgtggaat aattcagctc 2641 acagtgcaag agcccccaga ccctcccgaa attgagatca aagatgtcaa agcacgcaca 2701 attacgctca ggtggaccat ggggtttgat ggaaacagtc ccatcacagg ctacgatatt 2761 gaatgcaaaa ataaatcaga ctcctgggat tctgctcaga gaaccaaaga tgtttcccct 2821 cagctgaact cggccaccat cattgatatc cacccttcct ccacctacag catccgcatg 2881 tacgccaaga accggattgg caagagcgag cccagcaacg agctcaccat cacggcggac 2941 gaggcagctc ctgatggtcc acctcaggaa gttcacctgg agcctatatc atctcagagc 3001 atcagggtca catggaaggc tcccaagaaa catttgcaaa atgggattat ccgtggctac 3061 caaataggtt accgagagta cagcactggg ggtaacttcc aattcaacat tatcagtgtc 3121 gacaccagcg gggacagtga ggtttacacc ctggacaacc tgaataagtt cactcagtac 3181 ggcctggtgg tgcaggcctg taaccgggcc ggcacggggc cttcttctca ggaaatcatc 3241 accaccactc tcgaggatgt gcccagttac ccccccgaaa atgtccaagc catagcaaca 3301 tcaccagaaa gcatatcaat atcctggtcc acactttcca aggaagcctt gaatggaatt 3361 ctccaggggt tcagagtcat ttactgggcc aacctcatgg acggagagct gggtgagatt 3421 aaaaacatca ccaccacaca gccttcactg gagctggacg ggctggaaaa gtacaccaac 3481 tacagcatcc aggtgctggc cttcacccgc gcaggagacg gggtcaggag tgagcagatc 3541 ttcacccgga ccaaagagga tgttccaggt cctcccgcgg gtgtgaaggc agcggcggcc 3601 tcagcctcca tggtctttgt gtcctggctt ccccctctca agctgaacgg catcatccga 3661 aagtacactg tattctgctc ccacccctat cccacagtga tcagcgagtt tgaggcctct 3721 cccgactcgt tttcctacag aattcccaac ctgagtagga atcgtcagta cagcgtctgg 3781 gtggtggctg ttacttcagc cggaagaggc aacagcagtg aaatcatcac agtcgagcca 3841 ctagcaaaag ctcctgcacg aatcctgacc ttcagtggga cagtgactac tccatggatg 3901 aaagacattg tcttgccttg taaggctgtt ggggaccctt ctcctgcagt caaatggatg 3961 aaagacagta acgggacacc cagtctagta acgattgatg ggcggaggag catctttagc 4021 aacggaagct tcattattcg cacggtgaaa gcagaagact ccggctatta cagctgcatt 4081 gccaataaca actggggatc tgatgaaatt attttaaact tacaagtaca agttccacca 4141 gatcagcctc ggcttacagt ctccaagacc acgtcttcct ccatcaccct ttcttggctc 4201 cctggagaca acgggggcag ctctatcaga ggatacatac tgcagtactc cgaggacaat 4261 agtgagcagt gggggagttt tccaatcagc cccagcgaac gttcctatcg cttggaaaat 4321 ctcaaatgtg ggacttggta taagttcaca ctgacagccc aaaatggagt gggcccaggg 4381 cgcataagtg aaatcataga agcaaagacc ttaggaaaag agccccagtt ctcaaaggag 4441 caggagctgt ttgccagcat caacaccaca cgcgtgaggc tgaacctcat tggctggaat 4501 gatggcggct gccccatcac ctccttcaca ctagagtaca ggccctttgg gaccacagtt 4561 tggaccacag ctcagaggac ctctctctcc aagtcctaca tcctgtatga cctgcaggaa 4621 gccacctggt atgagctgca gatgcgggtg tgcaacagtg cgggctgcgc ggagaagcag 4681 gccaacttcg ctacgctgaa ctacgatggc agtacaattc ctccactcat taagtcagtt 4741 gtccaaaacg aagaagggct gacgaccaac gaggggctca agatgctggt gaccatctcc 4801 tgtatcctgg tgggggtctt gctgctgttt gtgctcctgc tggttgtgcg gaggaggcgg 4861 cgggagcaga ggctaaagag gctgcgagat gcaaagagtt tagctgaaat gctcatgagt 4921 aagaataccc ggacttcaga tacgttaagc aagcaacagc agaccctgcg aatgcacatc 4981 gacataccca gggctcagct tttgattgaa gagagagaca cgatggagac cattgatgat 5041 cgctccacgg ttctgttgac ggatgctgac tttggagagg cagctaagca gaagtccctg 5101 acggtcactc acacggtcca ttaccaatcg gtgtctcagg ccactgggcc cttagtggat 5161 gtttcagacg ctcggccggg aacgaatccc accaccagga ggaatgccaa ggctgggccc 5221 acagcgagaa accgctatgc cagccagtgg accctcaacc gaccccaccc caccatctca 5281 gcacacaccc tcaccacaga ctggaggctg ccaacaccca gggctgcagg atcagtagac 5341 aaagagagcg acagttacag cgtcagcccc tcgcaagaca cagatcgagc aagaagcagc 5401 atggtctcca cagaaagtgc ctcctccact tacgaagaac tggccagggc ctacgaacac 5461 gccaagatgg aagagcaact gaggcacgcc aagttcacca tcacggagtg cttcatatca 5521 gacacgtcat cggagcagtt gacggcaggg acaaatgagt acacggacag tctgacctcc 5581 agcacccctt ccgaatcggg aatctgcagg ttcactgcat ctccccccaa acctcaggat 5641 ggaggaagag taatgaatat ggcagttcca aaggcacatc ggccaggtga cctcatacat 5701 ttgcctccat accttagaat ggactttttg ttaaaccgag gtggtccagg caccagcagg 5761 gacctgagct taggacaagc atgcttggaa cctcagaaaa gccggaccct gaagcgcccc 5821 acggtcctgg agcccatccc gatggaagcc gcctcctccg cctcctccac gagagaagga 5881 cagtcgtggc agccgggggc cgtggccaca ttacctcagc gggagggagc agagctggga 5941 caggcagcta aaatgagcag ctcccaagaa tcactgctcg actcccgggg ccatttgaaa 6001 ggaaacaatc cttacgcaaa atcttacacc ctggtataa
Nucleotide sequence in FASTA format (without gaps)
DSCAM*01
Amino acid sequence
1 MWILALSLFQ SFANVFSEDL HSSLYFVNAS LQEVVFASTT GTLVPCPAAG IPPVTLRWYL 61 ATGEEIYDVP GIRHVHPNGT LQIFPFPPSS FSTLIHDNTY YCTAENPSGK IRSQDVHIKA 121 VLREPYTVRV EDQKTMRGNV AVFKCIIPSS VEAYITVVSW EKDTVSLVSG SRFLITSTGA 181 LYIKDVQNED GLYNYRCITR HRYTGETRQS NSARLFVSDP ANSAPSILDG FDHRKAMAGQ 241 RVELPCKALG HPEPDYRWLK DNMPLELSGR FQKTVTGLLI ENIRPSDSGS YVCEVSNRYG 301 TAKVIGRLYV KQPLKATISP RKVKSSVGSQ VSLSCSVTGT EDQELSWYRN GEILNPGKNV 361 RITGINHENL IMDHMVKSDG GAYQCFVRKD KLSAQDYVQV VLEDGTPKII SAFSEKVVSP 421 AEPVSLMCNV KGTPLPTITW TLDDDPILKG GSHRISQMIT SEGNVVSYLN ISSSQVRDGG 481 VYRCTANNSA GVVLYQARIN VRGPASIRPM KNITAIAGRD TYIHCRVIGY PYYSIKWYKN 541 SNLLPFNHRQ VAFENNGTLK LSDVQKEVDE GEYTCNVLVQ PQLSTSQSVH VTVKVPPFIQ 601 PFEFPRFSIG QRVFIPCVVV SGDLPITITW QKDGRPIPGS LGVTIDNIDF TSSLRISNLS 661 LMHNGNYTCI ARNEAAAVEH QSQLIVRVPP KFVVQPRDQD GIYGKAVILN CSAEGYPVPT 721 IVWKFSKGAG VPQFQPIALN GRIQVLSNGS LLIKHVVEED SGYYLCKVSN DVGADVSKSM 781 YLTVKIPAMI TSYPNTTLAT QGQKKEMSCT AHGEKPIIVR WEKEDRIINP EMARYLVSTK 841 EVGEEVISTL QILPTVREDS GFFSCHAINS YGEDRGIIQL TVQEPPDPPE IEIKDVKART 901 ITLRWTMGFD GNSPITGYDI ECKNKSDSWD SAQRTKDVSP QLNSATIIDI HPSSTYSIRM 961 YAKNRIGKSE PSNELTITAD EAAPDGPPQE VHLEPISSQS IRVTWKAPKK HLQNGIIRGY 1021 QIGYREYSTG GNFQFNIISV DTSGDSEVYT LDNLNKFTQY GLVVQACNRA GTGPSSQEII 1081 TTTLEDVPSY PPENVQAIAT SPESISISWS TLSKEALNGI LQGFRVIYWA NLMDGELGEI 1141 KNITTTQPSL ELDGLEKYTN YSIQVLAFTR AGDGVRSEQI FTRTKEDVPG PPAGVKAAAA 1201 SASMVFVSWL PPLKLNGIIR KYTVFCSHPY PTVISEFEAS PDSFSYRIPN LSRNRQYSVW 1261 VVAVTSAGRG NSSEIITVEP LAKAPARILT FSGTVTTPWM KDIVLPCKAV GDPSPAVKWM 1321 KDSNGTPSLV TIDGRRSIFS NGSFIIRTVK AEDSGYYSCI ANNNWGSDEI ILNLQVQVPP 1381 DQPRLTVSKT TSSSITLSWL PGDNGGSSIR GYILQYSEDN SEQWGSFPIS PSERSYRLEN 1441 LKCGTWYKFT LTAQNGVGPG RISEIIEAKT LGKEPQFSKE QELFASINTT RVRLNLIGWN 1501 DGGCPITSFT LEYRPFGTTV WTTAQRTSLS KSYILYDLQE ATWYELQMRV CNSAGCAEKQ 1561 ANFATLNYDG STIPPLIKSV VQNEEGLTTN EGLKMLVTIS CILVGVLLLF VLLLVVRRRR 1621 REQRLKRLRD AKSLAEMLMS KNTRTSDTLS KQQQTLRMHI DIPRAQLLIE ERDTMETIDD 1681 RSTVLLTDAD FGEAAKQKSL TVTHTVHYQS VSQATGPLVD VSDARPGTNP TTRRNAKAGP 1741 TARNRYASQW TLNRPHPTIS AHTLTTDWRL PTPRAAGSVD KESDSYSVSP SQDTDRARSS 1801 MVSTESASST YEELARAYEH AKMEEQLRHA KFTITECFIS DTSSEQLTAG TNEYTDSLTS 1861 STPSESGICR FTASPPKPQD GGRVMNMAVP KAHRPGDLIH LPPYLRMDFL LNRGGPGTSR 1921 DLSLGQACLE PQKSRTLKRP TVLEPIPMEA ASSASSTREG QSWQPGAVAT LPQREGAELG 1981 QAAKMSSSQE SLLDSRGHLK GNNPYAKSYT LV*
Amino acid sequence in FASTA format (without gap)
DSCAM*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: C-LIKE-DOMAIN on one layer [D1], [D2], [D3], [D4], [D5], [D6], [D7], [D8], [D9], [D10], C-LIKE-DOMAIN on two layers [D1], [D2], [D3], [D4], [D5], [D6], [D7], [D8], [D9], [D10]
External links
Nomenclature
- HGNC: 3039
Genome database
Sequence database
- EMBL: AL163283, AL163282, AL163281, AB209136, AF217525, AF023449, AF023450, AF289030
- GenBank: AL163283, AL163282, AL163281, AB209136, AF217525, AF023449, AF023450, AF289030
- DDBJ: AL163283, AL163282, AL163281, AB209136, AF217525, AF023449, AF023450, AF289030
- Swiss-Prot: O60469
- TrEMBL: Q59GH3, Q8WY19
- NCBI: NM_001380, NP_001380, NM_206887, NP_996770
Structure database
- PDB:
Created: 23/05/2007
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2024 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT