
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens FCGR1C
Citing IMGT RPI entry for FCGR1C
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens FCGR1C
- IMGT gene definition: Fc fragment of IgG, high affinity Ic, Receptor for(CD64)
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1q21.1
Gene exon/intron organization
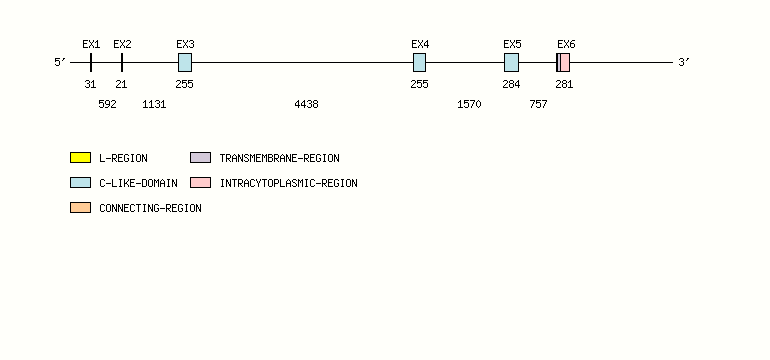
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 1
IMGT reference alleles
| Allele name | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Clone names | Accession numbers | Molecule type | ||
| FCGR1C*01 | F | M91647 [1] | gDNA | |
IMGT reference sequences (in FASTA format) for the allele(s): FCGR1C*01
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Corresponding protein database accession numbers
| Allele name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| FCGR1C*01 | M91647 | 210 aa | ||
IMGT references:
- [1] Ernst, L.K. et al, J. Biol. Chem., 267, 15692-15700 (1992). PMID:1379234
Genomic sequence
Genomic sequence from M91647Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
FCGR1C*01: M91647(g)
Nucleotide sequence
1 atgtggttct tgacaactct gctcctttgg gttccagttg atgggcaagt ggacaccaca 61 aaggcagtga tcactttgca gcctccatgg gtcagcgtgt tccaagagga aaccgtaacc 121 ttgcactgtg aggtgctcca tctgcctggg agcagctcca cacagtggtt tctcaatggc 181 acagccactc agacctcgac ccccagctac agaatcacct ctgccagtgt caatgacagt 241 ggtgaataca ggtgccagag aggtctctca gggcgaagtg accccataca gctggaaatc 301 cacagaggct ggccactact gcaggtctcc agcagagtct tcacggaagg agaacctctg 361 gccttgaggt gtcatgcgtg gaaggataag ctggtgtaca atgtgcttta ctatcgaaat 421 ggcaaagcct ttaagttttt ccactggaat tctaacctca ccattctgaa aaccaacata 481 agtcacaatg gcacctacca ttgctcaggc aagggaaagc atcactacac atcagcagga 541 atatcacaat acactgtgaa agagctattt ccagctccag tgctgaatgc atctgtgaca 601 tccccactcc tggggggaat ctggtcaccc tgagctgtga aacaaagttg ctcttgcaga 661 ggcctggttt gcagctttac ttctccttct acatgggcag caagaccctg cgaggcagga 721 acacatcctc tgaatactaa atactaactg ctagaagaga agactctggg ttatactggt 781 gcgaggctgc cacagaggat ggaaatgtcc ttaagcgcag ccctgagttg gagcttcaag 841 tgcttggcct ccagttacca actcctgtct ggtttcatgt ccttttctat ctggcagtgg 901 gaataatgtt tttagtgaac actgttctct gggtgacaat acgtaaagaa ctgaaaagaa 961 agaaaaagtg gaatttagaa atctctttgg attctggtca tgagaagaag gtaatttcca 1021 gccttcaaga agacagacat ttagaagaag agctgaaatg tcaggaacaa aaagaagaac 1081 agctgcagga aggggtgcac cggaaggagc cccagggggc cacgtag
Nucleotide sequence in FASTA format (without gaps)
FCGR1C*01
Amino acid sequence
1 MWFLTTLLLW VPVDGQVDTT KAVITLQPPW VSVFQEETVT LHCEVLHLPG SSSTQWFLNG 61 TATQTSTPSY RITSASVNDS GEYRCQRGLS GRSDPIQLEI HRGWPLLQVS SRVFTEGEPL 121 ALRCHAWKDK LVYNVLYYRN GKAFKFFHWN SNLTILKTNI SHNGTYHCSG KGKHHYTSAG 181 ISQYTVKELF PAPVLNASVT SPLLGGIWSP *AVKQSCSCR GLVCSFTSPS TWAARPCEAG 241 THPLNTKY*L LEEKTLGYTG ARLPQRMEMS LSAALSWSFK CLASSYQLLS GFMSFSIWQW 301 E*CF**TLFS G*QYVKN*KE RKSGI*KSLW ILVMRRR*FP AFKKTDI*KK S*NVRNKKKN 361 SCRKGCTGRS PRGPR
Amino acid sequence in FASTA format (without gap)
FCGR1C*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays: C-LIKE-DOMAIN
- IMGT Collier de perles: C-LIKE-DOMAIN on one layer, C-LIKE-DOMAIN on two layers
External links
Genome databases
Sequence databases
Structure database
- PDB:
Created: 30/07/2004
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Bertrand Monnier
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Bertrand Monnier
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2024 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT