
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens FCGRT
IMGT gene name and definition
- IMGT gene name: Homo sapiens FCGRT
- IMGT gene definition: Fc fragment of IgG, receptor, transporter, alpha
Chromosomal localization
- Chromosome: 19
- Chromosomal localization: 19q13.3
Gene exon/intron organization
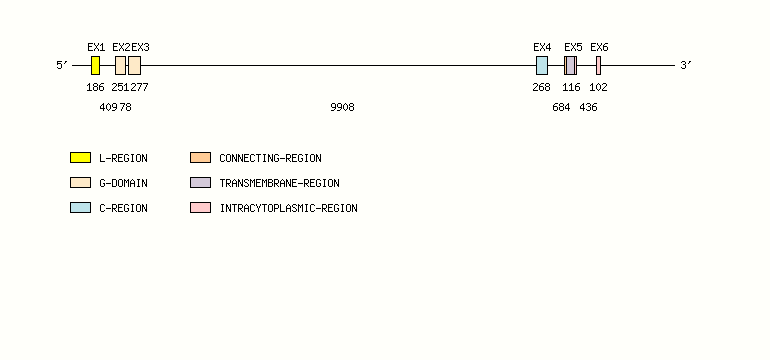
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 2
IMGT reference alleles
| Allele name | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Clone names | Accession numbers | Molecule type | ||
| FCGRT*01 | F | AF220542 | gDNA | |
| FCGRT*02 | F | AF200219 | gDNA | |
IMGT reference sequences (in FASTA format) for the allele(s): FCGRT*01 to FCGRT*02
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele name | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Clone names | Accession numbers | Molecule type | ||
| FCGRT*01 | F | U12255 | cDNA | |
Corresponding protein database accession numbers
| Allele name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| FCGRT*01 | AF220542 | Sw: P55899 | 365 aa | |
| FCGRT*02 | AF200219 | 362 aa | ||
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
FCGRT*01: AF220542(g) U12255(c)
Nucleotide sequence
1 atgggggtcc cgcggcctca gccctgggcg ctggggctcc tgctctttct ccttcctggg 61 agcctgggcg cagaaagcca cctctccctc ctgtaccacc ttaccgcggt gtcctcgcct 121 gccccgggga ctcctgcctt ctgggtgtcc ggctggctgg gcccgcagca gtacctgagc 181 tacaatagcc tgcggggcga ggcggagccc tgtggagctt gggtctggga aaaccaggtg 241 tcctggtatt gggagaaaga gaccacagat ctgaggatca aggagaagct ctttctggaa 301 gctttcaaag ctttgggggg aaaaggtccc tacactctgc agggcctgct gggctgtgaa 361 ctgggccctg acaacacctc ggtgcccacc gccaagttcg ccctgaacgg cgaggagttc 421 atgaatttcg acctcaagca gggcacctgg ggtggggact ggcccgaggc cctggctatc 481 agtcagcggt ggcagcagca ggacaaggcg gccaacaagg agctcacctt cctgctattc 541 tcctgcccgc accgcctgcg ggagcacctg gagaggggcc gcggaaacct ggagtggaag 601 gaccccccct ccatgcgcct gaaggcccga cccagcagcc ctggcttttc cgtgcttacc 661 tgcagcgcct tctccttcta ccctccggag ctgcaacttc ggttcctgcg gaatgggctg 721 gccgctggca ccggccaggg tgacttcggc cccaacagtg acggatcctt ccacgcctcg 781 tcgtcactaa cagtcaaaag tggcgatgag caccactact gctgcattgt gcagcacgcg 841 gggctggcgc agcccctcag ggtggagctg gaatctccag ccaagtcctc cgtgctcgtg 901 gtgggaatcg tcatcggtgt cttgctactc acggcagcgg ctgtaggagg agctctgttg 961 tggagaagga tgaggagtgg gctgccagcc ccatggatct cccttcgtgg agacgacacc 1021 ggggtcctcc tgcccacccc aggggaggcc caggatgctg atttgaagga tgtaaatgtg 1081 attccagcca ccgcctga
Nucleotide sequence in FASTA format (without gaps)
FCGRT*01
Amino acid sequence
1 MGVPRPQPWA LGLLLFLLPG SLGAESHLSL LYHLTAVSSP APGTPAFWVS GWLGPQQYLS 61 YNSLRGEAEP CGAWVWENQV SWYWEKETTD LRIKEKLFLE AFKALGGKGP YTLQGLLGCE 121 LGPDNTSVPT AKFALNGEEF MNFDLKQGTW GGDWPEALAI SQRWQQQDKA ANKELTFLLF 181 SCPHRLREHL ERGRGNLEWK DPPSMRLKAR PSSPGFSVLT CSAFSFYPPE LQLRFLRNGL 241 AAGTGQGDFG PNSDGSFHAS SSLTVKSGDE HHYCCIVQHA GLAQPLRVEL ESPAKSSVLV 301 VGIVIGVLLL TAAAVGGALL WRRMRSGLPA PWISLRGDDT GVLLPTPGEA QDADLKDVNV 361 IPATA*
Amino acid sequence in FASTA format (without gap)
FCGRT*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays (MHC): G-LIKE-DOMAINs
- IMGT Collier de perles: G-LIKE-DOMAIN on one layer, C-LIKE-DOMAIN on one layer, C-LIKE-DOMAIN on two layers
IMGT databases
- IMGT/3Dstructure-DB: 1exu
External links
Nomenclature
- HGNC: 3621
Genome databases
- Entrez Gene: 2217
- GENATLAS:
- GeneCards: GC19P054707
- GDB:
- OMIM: 601437
Sequence databases
- EMBL: AF220542, U12255, AF200219
- GenBank: AF220542, U12255, AF200219
- DDBJ: AF220542, U12255, AF200219
- Swiss-Prot: P55899
- TrEMBL:
- NCBI: NM_004107
Structure database
Created: 30/07/2004
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Alain Carnec
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Alain Carnec
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2024 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT