
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens HFE
IMGT gene name and definition
- IMGT gene name: Homo sapiens HFE
- IMGT gene definition: hemochromatosis
Chromosomal localization
- Chromosome: 6
- Chromosomal localization: 6p21.3
Gene exon/intron organization
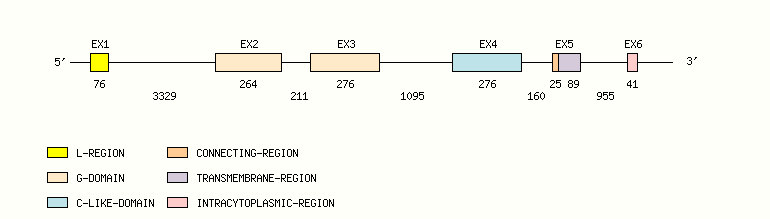
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 2
IMGT reference alleles
| Allele name | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Clone names | Accession numbers | Molecule type | ||
| HFE*01 | F | Z92910 | gDNA | |
| HFE*02 | F | gDNA [1] | ||
IMGT reference sequences (in FASTA format) for the allele(s): HFE*01 to HFE*02
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele name | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Clone names | Accession numbers | Molecule type | ||
| HFE*01 | F | U91328 | gDNA | |
| U60319 | mRNA | |||
| AF079408 | cDNA splicing B (1) | |||
| AF079407 | cDNA splicing C (2) | |||
| AF079409 | cDNA splicing D (3) | |||
| AJ249335 | cDNA splicing E (4) | |||
| AJ250635 | cDNA splicing F (5) | |||
| AF144242 | cDNA splicing G (6) | |||
| AF149804 | cDNA splicing H (7) | |||
Corresponding protein database accession numbers
| Allele name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| HFE*01 | U60319 | NP_000401 | 348 aa | |
| AF079408 | NP_620576 | 250 aa | (1) | |
| AF079407 | NP_620575 | 334 aa | (2) | |
| AF079409 | NP_620577 | 236 aa | (3) | |
| AJ249335 | NP_620578 | 325 aa | (4) | |
| AJ250635 | NP_620579 | 168 aa | (5) | |
| AF144242 | NP_620573 | 256 aa | (6) | |
| AF149804 | NP_620572 | 242 aa | (7) | |
| HFE*02 | ||||
IMGT notes:
- (1) Alternative splicing,missing exon 2.
- (2) Alternative splicing, missing part of exon 4.
- (3) Alternative splicing, missing exon 2 and part of exon 4.
- (4) Alternative splicing, missing part of exon 2.
- (5) Alternative splicing, missing exon 2 and exon 3.
- (6) Alternative splicing, missing exon 3.
- (7) Alternative splicing, missing exon 3 and part of exon 4.
IMGT references:
- [1] Ahouse, J. J. et al., J. Immun. 151, 6076-6088 (1993). PMID:7504013
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
Nucleotide sequence
1 atgggcccgc gagccaggcc ggcgcttctc ctcctgatgc ttttgcagac cgcggtcctg 61 caggggcgct tgctgcgttc acactctctg cactacctct tcatgggtgc ctcagagcag 121 gaccttggtc tttccttgtt tgaagctttg ggctacgtgg atgaccagct gttcgtgttc 181 tatgatcatg agagtcgccg tgtggagccc cgaactccat gggtttccag tagaatttca 241 agccagatgt ggctgcagct gagtcagagt ctgaaagggt gggatcacat gttcactgtt 301 gacttctgga ctattatgga aaatcacaac cacagcaagg agtcccacac cctgcaggtc 361 atcctgggct gtgaaatgca agaagacaac agtaccgagg gctactggaa gtacgggtat 421 gatgggcagg accaccttga attctgccct gacacactgg attggagagc agcagaaccc 481 agggcctggc ccaccaagct ggagtgggaa aggcacaaga ttcgggccag gcagaacagg 541 gcctacctgg agagggactg ccctgcacag ctgcagcagt tgctggagct ggggagaggt 601 gttttggacc aacaagtgcc tcctttggtg aaggtgacac atcatgtgac ctcttcagtg 661 accactctac ggtgtcgggc cttgaactac tacccccaga acatcaccat gaagtggctg 721 aaggataagc agccaatgga tgccaaggag ttcgaaccta aagacgtatt gcccaatggg 781 gatgggacct accagggctg gataaccttg gctgtacccc ctggggaaga gcagagatat 841 acgtgccagg tggagcaccc aggcctggat cagcccctca ttgtgatctg ggagccctca 901 ccgtctggca ccctagtcat tggagtcatc agtggaattg ctgtttttgt cgtcatcttg 961 ttcattggaa ttttgttcat aatattaagg aagaggcagg gttcaagagg agccatgggg 1021 cactacgtct tagctgaacg tgagtga
Nucleotide sequence in FASTA format (without gaps)
HFE*01
Amino acid sequence
1 MGPRARPALL LLMLLQTAVL QGRLLRSHSL HYLFMGASEQ DLGLSLFEAL GYVDDQLFVF 61 YDHESRRVEP RTPWVSSRIS SQMWLQLSQS LKGWDHMFTV DFWTIMENHN HSKESHTLQV 121 ILGCEMQEDN STEGYWKYGY DGQDHLEFCP DTLDWRAAEP RAWPTKLEWE RHKIRARQNR 181 AYLERDCPAQ LQQLLELGRG VLDQQVPPLV KVTHHVTSSV TTLRCRALNY YPQNITMKWL 241 KDKQPMDAKE FEPKDVLPNG DGTYQGWITL AVPPGEEQRY TCQVEHPGLD QPLIVIWEPS 301 PSGTLVIGVI SGIAVFVVIL FIGILFIILR KRQGSRGAMG HYVLAERE*
Amino acid sequence in FASTA format (without gap)
HFE*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays (MHC): G-LIKE-DOMAINs
- IMGT Collier de perles: G-LIKE-DOMAINs on one layer, C-LIKE-DOMAIN on one layer, C-LIKE-DOMAIN on two layers
IMGT databases
- IMGT/3Dstructure-DB: 1de4
External links
Nomenclature
- HGNC: 4886
Genome databases
- Entrez Gene: 3077
- GeneCards: GC06P026195
- OMIM: 235200
Sequence databases
- EMBL: Z92910, U91328, U60319, AF079408, AF079407, AF079409, AJ249335, AJ250635, AF144242, AF149804
- GenBank: Z92910, U91328, U60319, AF079408, AF079407, AF079409, AJ249335, AJ250635, AF144242, AF149804
- DDBJ: Z92910, U91328, U60319, AF079408, AF079407, AF079409, AJ249335, AJ250635, AF144242, AF149804
- Swiss-Prot: Q30201
- NCBI: NP_000401, NP_620576, NP_620575, NP_620577, NP_620578, NP_620579, NP_620573, NP_620572
Structure database
- PDB: 1DE4
Created: 30/07/2004
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Alain Carnec
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Alain Carnec
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2024 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT