
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens VCAM1
Citing IMGT RPI entry for VCAM1
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens VCAM1
- IMGT gene definition: Homo sapiens Vascular cell adhesion molecule 1
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1p32-p31
Gene exon/intron organization
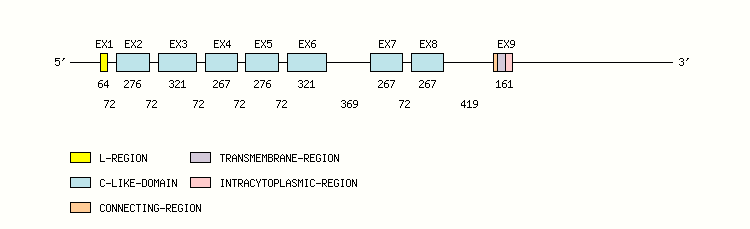
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 3
IMGT reference alleles
| Allele name | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| VCAM1*01 | F | EX1-9 | M73255 [1] | gDNA |
| VCAM1*02 | F | EX1-9 | AC093428 (3686..22990) | gDNA (1) |
| VCAM1*03 | F | EX1-9 | AK223266 | cDNA (2) |
IMGT reference sequences (in FASTA format) for the allele(s): VCAM1*01 to VCAM1*03
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele name | Gene functionality | IMGT reference sequences | Partiality | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| VCAM1*01 | F | EX1-9 | AF536818 | gDNA | |
| BC017276 | cDNA | ||||
| BC068490 | cDNA | ||||
| BC085003 | cDNA | ||||
| M60335 | cDNA | ||||
| EX1-4, EX6-9 | M30257 [2] | cDNA splicing B (3) | |||
| NM080682 | cDNA splicing B | partial | |||
| EX1-9 | X53051 | cDNA | |||
| EX1-3 | AU121762 | cDNA | |||
| EX1 | M92431 | gDNA | |||
| S50587 | gDNA | ||||
| EX9 | CR749464 | cDNA | |||
| EX1-9 | NM001078 | cDNA | partial | ||
| VCAM1*02 | F | EX1-9 | CR617596 | cDNA | |
| EX6-9 | CR603251 | cDNA | |||
Corresponding protein database accession numbers
| Allele Name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| VCAM1*01 | M73255 | P19320 | 739 aa | 1 |
| CR749464 | Q68DC4 | 53 aa | 1 | |
| NM001078 | NP001069 | 739 aa | 1 | |
| NM080682 | NP542413 | 647 aa | 2 | |
| VCAM1*02 | AC093428 (3686..22990) | P19320 | 739 aa | 1 |
| VCAM1*03 | AK223266 | Q53FL7 | 739 aa | 1 |
IMGT notes:
- (1) In EX9 149a>g.
- (2) In EX5 [D4] 45.2t>c; 15.1I>T, numbering according to IMGT unique numbering for C-DOMAIN and C-LIKE-DOMAIN.
- (3) Splicing B. No EX5.
IMGT references:
- [1] Cybulsky M.I. et al., Proc. Natl. Acad. Sci. U.S.A. 88, 7859-7863 (1991). PMID:1715583
- [2] Osborn L. et al., Cell 59, 1203-1211 (1989). PMID:2688898
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
VCAM1*01: M73255(g)
Nucleotide sequence
1 atgcctggga agatggtcgt gatccttgga gcctcaaata tactttggat aatgtttgca 61 gcttctcaag cttttaaaat cgagaccacc ccagaatcta gatatcttgc tcagattggt 121 gactccgtct cattgacttg cagcaccaca ggctgtgagt ccccattttt ctcttggaga 181 acccagatag atagtccact gaatgggaag gtgacgaatg aggggaccac atctacgctg 241 acaatgaatc ctgttagttt tgggaacgaa cactcttacc tgtgcacagc aacttgtgaa 301 tctaggaaat tggaaaaagg aatccaggtg gagatctact cttttcctaa ggatccagag 361 attcatttga gtggccctct ggaggctggg aagccgatca cagtcaagtg ttcagttgct 421 gatgtatacc catttgacag gctggagata gacttactga aaggagatca tctcatgaag 481 agtcaggaat ttctggagga tgcagacagg aagtccctgg aaaccaagag tttggaagta 541 acctttactc ctgtcattga ggatattgga aaagttcttg tttgccgagc taaattacac 601 attgatgaaa tggattctgt gcccacagta aggcaggctg taaaagaatt gcaagtctac 661 atatcaccca agaatacagt tatttctgtg aatccatcca caaagctgca agaaggtggc 721 tctgtgacca tgacctgttc cagcgagggt ctaccagctc cagagatttt ctggagtaag 781 aaattagata atgggaatct acagcacctt tctggaaatg caactctcac cttaattgct 841 atgaggatgg aagattctgg aatttatgtg tgtgaaggag ttaatttgat tgggaaaaac 901 agaaaagagg tggaattaat tgttcaagag aaaccattta ctgttgagat ctcccctgga 961 ccccggattg ctgctcagat tggagactca gtcatgttga catgtagtgt catgggctgt 1021 gaatccccat ctttctcctg gagaacccag atagacagcc ctctgagcgg gaaggtgagg 1081 agtgagggga ccaattccac gctgaccctg agccctgtga gttttgagaa cgaacactct 1141 tatctgtgca cagtgacttg tggacataag aaactggaaa agggaatcca ggtggagctc 1201 tactcattcc ctagagatcc agaaatcgag atgagtggtg gcctcgtgaa tgggagctct 1261 gtcactgtaa gctgcaaggt tcctagcgtg tacccccttg accggctgga gattgaatta 1321 cttaaggggg agactattct ggagaatata gagtttttgg aggatacgga tatgaaatct 1381 ctagagaaca aaagtttgga aatgaccttc atccctacca ttgaagatac tggaaaagct 1441 cttgtttgtc aggctaagtt acatattgat gacatggaat tcgaacccaa acaaaggcag 1501 agtacgcaaa cactttatgt caatgttgcc cccagagata caaccgtctt ggtcagccct 1561 tcctccatcc tggaggaagg cagttctgtg aatatgacat gcttgagcca gggctttcct 1621 gctccgaaaa tcctgtggag caggcagctc cctaacgggg agctacagcc tctttctgag 1681 aatgcaactc tcaccttaat ttctacaaaa atggaagatt ctggggttta tttatgtgaa 1741 ggaattaacc aggctggaag aagcagaaag gaagtggaat taattatcca agttactcca 1801 aaagacataa aacttacagc ttttccttct gagagtgtca aagaaggaga cactgtcatc 1861 atctcttgta catgtggaaa tgttccagaa acatggataa tcctgaagaa aaaagcggag 1921 acaggagaca cagtactaaa atctatagat ggcgcctata ccatccgaaa ggcccagttg 1981 aaggatgcgg gagtatatga atgtgaatct aaaaacaaag ttggctcaca attaagaagt 2041 ttaacacttg atgttcaagg aagagaaaac aacaaagact atttttctcc tgagcttctc 2101 gtgctctatt ttgcatcctc cttaataata cctgccattg gaatgataat ttactttgca 2161 agaaaagcca acatgaaggg gtcatatagt cttgtagaag cacagaaatc aaaagtgtag
Nucleotide sequence in FASTA format (without gaps)
VCAM1*01
Amino acid sequence
1 MPGKMVVILG ASNILWIMFA ASQAFKIETT PESRYLAQIG DSVSLTCSTT GCESPFFSWR 61 TQIDSPLNGK VTNEGTTSTL TMNPVSFGNE HSYLCTATCE SRKLEKGIQV EIYSFPKDPE 121 IHLSGPLEAG KPITVKCSVA DVYPFDRLEI DLLKGDHLMK SQEFLEDADR KSLETKSLEV 181 TFTPVIEDIG KVLVCRAKLH IDEMDSVPTV RQAVKELQVY ISPKNTVISV NPSTKLQEGG 241 SVTMTCSSEG LPAPEIFWSK KLDNGNLQHL SGNATLTLIA MRMEDSGIYV CEGVNLIGKN 301 RKEVELIVQE KPFTVEISPG PRIAAQIGDS VMLTCSVMGC ESPSFSWRTQ IDSPLSGKVR 361 SEGTNSTLTL SPVSFENEHS YLCTVTCGHK KLEKGIQVEL YSFPRDPEIE MSGGLVNGSS 421 VTVSCKVPSV YPLDRLEIEL LKGETILENI EFLEDTDMKS LENKSLEMTF IPTIEDTGKA 481 LVCQAKLHID DMEFEPKQRQ STQTLYVNVA PRDTTVLVSP SSILEEGSSV NMTCLSQGFP 541 APKILWSRQL PNGELQPLSE NATLTLISTK MEDSGVYLCE GINQAGRSRK EVELIIQVTP 601 KDIKLTAFPS ESVKEGDTVI ISCTCGNVPE TWIILKKKAE TGDTVLKSID GAYTIRKAQL 661 KDAGVYECES KNKVGSQLRS LTLDVQGREN NKDYFSPELL VLYFASSLII PAIGMIIYFA 721 RKANMKGSYS LVEAQKSKV*
Amino acid sequence in FASTA format (without gap)
VCAM1*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- IMGT Alignment of alleles:
- IMGT Protein displays:
- IMGT Collier de perles: C-LIKE-DOMAIN [D1] on one layer, C-LIKE-DOMAIN [D1] on two layers, C-LIKE-DOMAIN [D2] on one layer, C-LIKE-DOMAIN [D2] on two layers, C-LIKE-DOMAIN [D3] on one layer, C-LIKE-DOMAIN [D3] on two layers, C-LIKE-DOMAIN [D4] on one layer, C-LIKE-DOMAIN [D4] on two layers, C-LIKE-DOMAIN [D5] on one layer, C-LIKE-DOMAIN [D5] on two layers, C-LIKE-DOMAIN [D6] on one layer, C-LIKE-DOMAIN [D6] on two layers, C-LIKE-DOMAIN [D7] on one layer, C-LIKE-DOMAIN [D7] on two layers
IMGT databases
External links
Genome databases
- Entrez Gene: 7412
- GENATLAS: VCAM1
- GeneCards: GC01P100897
- GDB: VCAM1
- OMIM: 192225
Sequence databases
- EMBL: M30257, M60335, M73255, AF53681, BC017276, BC068490, BC085003, M92431
- GenBank: M30257, M60335, M73255, AF53681, BC017276, BC068490, BC085003, M92431
- DDBJ: M30257, M60335, M73255, AF53681, BC017276, BC068490, BC085003, M92431
- Swiss-Prot: P19320
- TrEMBL: Q53FL7
- NCBI: NM_001078, NP_001069, NM_080682, NP_542413
Structure database
Created: 20/02/2007
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Nelly Rozas, Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Nelly Rozas, Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2024 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT