
IMGT Repertoire (RPI)
Other B7 Family entries
IMGT RPI entry from gene to protein for Mus musculus B7H4
Citing IMGT RPI entry for B7H4
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Mus musculus B7H4
- IMGT gene definition: V-set domain containing T cell activation inhibitor 1
Chromosomal localization
- Chromosome: 3
- Chromosomal localization: 3 F2.2
Gene exon/intron organization
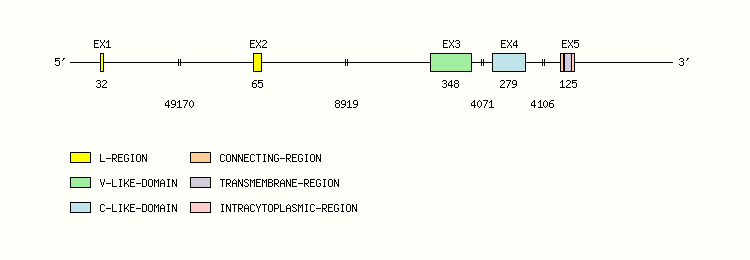
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 3
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| B7H4*01 | F | EX1-5 | AY322147 [1] | cDNA |
| B7H4*02 | F | EX1-5 | AK143276 | cDNA (1) |
| B7H4*03 | F | EX1-5 | BC032925 | cDNA (2) |
IMGT reference sequences (in FASTA format) for the allele(s): B7H4*01 to B7H4*03
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| B7H4*01 | F | EX1-5 | AK145664 | cDNA |
| AY280973 | cDNA | |||
| AY346099 | cDNA | |||
| NM_178594 | cDNA | |||
Corresponding protein database accession numbers
| Allele name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| B7H4*01 | AY322147 | Tr:Q7TSP5 | 283 aa | 1 |
| B7H4*02 | AK143276 | 283 aa | 1 | |
| B7H4*03 | BC032925 | Tr:Q8K091 | 283 aa | 1 |
| NM_178594 | NP_848709 | 283 aa | 1 | |
IMGT notes:
- (1) In EX5 g20>a, c36>t, c41>g, c47>t, c79>t; A27>V and g92>a.
- (2) In EX2 [D1], a322>t, T108>S and a336>g, positions according to IMGT unique numbering for V-DOMIAN and V-LIKE-DOMAIN. In EX3 [D2] c135>t and t237>c, positions according to IMGT unique numbering for C-DOMIAN and C-LIKE-DOMAIN. In EX5 c33>t, c38>g, c44>t, t64>c; F22>S, c79>t; A27>V and g92>a.
IMGT references:
- [1] Prasad D.V. et al. Immunity 18, 863-873 (2003). PMID:12818166
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
B7H4*01: AY322147(c)
Nucleotide sequence
1 atggcttcct tggggcagat catcttttgg agtattatta acatcatcat catcctggct 61 ggggccatcg cactcatcat tggctttggc atttcaggca agcacttcat cacggtcacg 121 accttcacct cagctggaaa cattggagag gacgggaccc tgagctgcac ttttgaacct 181 gacatcaaac tcaacggcat cgtcatccag tggctgaaag aaggcatcaa aggtttggtc 241 cacgagttca aagaaggcaa agacgacctc tcacagcagc atgagatgtt cagaggccgc 301 acagcagtgt ttgctgatca ggtggtagtt ggcaatgctt ccctgagact gaaaaacgtg 361 cagctcacgg atgctggcac ctacacatgt tacatccgca cctcaaaagg caaagggaat 421 gcaaaccttg agtataagac cggagccttc agtatgccag agataaatgt ggactataat 481 gccagttcag agagtttacg ctgcgaggct cctcggtggt tcccccagcc cacagtggcc 541 tgggcatctc aagtcgacca aggagccaat ttctcagaag tctccaacac cagctttgag 601 ttgaactctg agaatgtgac catgaaggtc gtatctgtgc tctacaatgt cacaatcaac 661 aacacatact cctgtatgat tgaaaacgac attgccaaag ccaccgggga catcaaagtg 721 acagattcag aggtcaaaag gcggagtcag ctgcagctgc tcaactccgg gccttccccg 781 tgtgtttttt cttctgcctt tgcggctggc tgggcgctcc tatctctctc ctgttgcctg 841 atgctaagat ga
Nucleotide sequence in FASTA format (without gaps)
B7H4*01
Amino acid sequence
1 MASLGQIIFW SIINIIIILA GAIALIIGFG ISGKHFITVT TFTSAGNIGE DGTLSCTFEP 61 DIKLNGIVIQ WLKEGIKGLV HEFKEGKDDL SQQHEMFRGR TAVFADQVVV GNASLRLKNV 121 QLTDAGTYTC YIRTSKGKGN ANLEYKTGAF SMPEINVDYN ASSESLRCEA PRWFPQPTVA 181 WASQVDQGAN FSEVSNTSFE LNSENVTMKV VSVLYNVTIN NTYSCMIEND IAKATGDIKV 241 TDSEVKRRSQ LQLLNSGPSP CVFSSAFAAG WALLSLSCCL MLR*
Amino acid sequence in FASTA format (without gap)
B7H4*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN on one layer, V-LIKE-DOMAIN on two layers, C-LIKE-DOMAIN on one layer, C-LIKE-DOMAIN on two layers
External links
Nomenclature
- HGNC:
Genome databases
Sequence databases
- EMBL: AY322147, AK143276, BC032925, AK145664, AY280973, AY346099
- GenBank: AY322147, AK143276, BC032925, AK145664, AY280973, AY346099
- DDBJ: AY322147, AK143276, BC032925, AK145664, AY280973, AY346099
- Swiss-Prot:
- TrEMBL: Q7TPH5, Q7TSP5, Q8K091
- NCBI: NM_178594, NP_848709
Structure databases
- PDB:
Created: 23/05/2007
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2024 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT