
IMGT Repertoire (RPI)
Other CD2 Family entries
IMGT RPI entry from gene to protein for Mus musculus CD244
Citing IMGT RPI entry for CD244
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Mus musculus CD244
- IMGT gene definition: CD244 natural killer cell receptor 2B4
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1 H3
Gene exon/intron organization
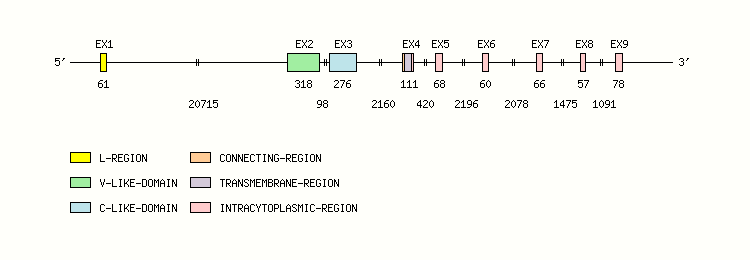
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 10
IMGT reference alleles
| Allele names | Gene functionality | Strains | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| CD244*01 | F | C57BL/6 | EX1-9 | L19057 [1] | cDNA |
| CD244*02 | F | C57BL/6J | EX1-9 | AK137505 | cDNA |
| CD244*03 | F | BALB/c | EX1-9 | AF184208 [2] | cDNA |
| CD244*04 | F | A.CA | EX1-9 | AF234831 | cDNA |
| CD244*05 | F | 129/SvJ | EX1-9 | AF234830 | cDNA |
| CD244*06 | F | NOD | EX1-9 | AK171232 | cDNA |
| CD244*07 | F | MRL/MpJ | EX1-9 | AB196800 | cDNA |
| CD244*08 | F | NOD | EX1-5, EX10 | AK170167 | cDNA Splicing B (1) |
| CD244*09 | F | C57BL/6 | EX1-5, EX10 | AF082803[3] | cDNA Splicing B |
| CD244*10 | F | C57BL/6J | EX1-5, EX11 | AK171544 | cDNA Splicing C (2) |
IMGT reference sequences (in FASTA format) for the allele(s): CD244*01 to CD244*10
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | Strains | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| CD244*01 | F | EX1-9 | NM_018729 | cDNA | |
| CD244*07 | F | NZB/BINJ | EX1-9 | AB196801 | cDNA |
| NZW/LacJ | EX1-9 | AB196802 | |||
| BXSB/MpJ | EX1-9 | AB196803 | |||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| CD244*01 | L19057 | Q07763 | 398 aa | 1 |
| NM_018729 | NP_061199 | 398 aa | 1 | |
| CD244*02 | AK137505 | Tr:Q3UV86 | 397 aa | 1 |
| CD244*03 | AF184208 | Tr: Q9ESE5 | 399 aa | 1 |
| CD244*04 | AF234831 | Tr:Q07763 | 397 aa | 1 |
| CD244*05 | AF234830 | Tr: Q9JIE1 | 398 aa | 1 |
| CD244*06 | AK171232 | Tr:Q3TBI0 | 398 aa | 1 |
| CD244*07 | AK170167 | Tr:Q3TDI8 | 341 aa | 2 |
| CD244*08 | AF082803 | 341 aa | 2 | |
| CD244*09 | AK171544 | Tr:Q3TAZ | 312 aa | 3 |
IMGT notes:
- (1) Multiple sequence variations in each allele, hence can not be explained.
- (2) Splicing B (341 aa). No EX6-9. Utilize a novel exon (EX10) of 33 codons.
- (3) Splicing C (312 aa). No EX6-9. Utilize a novel exon (EX11) of 4 codons.
IMGT references:
- [1] Mathew P.A. et al, J. Immunol. 151 (10), 5328-5337 (1993). PMID:8228228
- [2] Kumaresan P.R., Immunogenetics 51 (8-9), 758-761 (2000). PMID:10941850
- [3] Stepp S.E. et al, Eur. J. Immunol. 29 (8), 2392-2399 (1999). PMID:10458751
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
CD244*01: L19057(c)
Nucleotide sequence
1 atgttggggc aagctgtcct gttcacaacc ttcctgctcc tcagggctca tcagggccaa 61 gactgcccag attcttctga agaagtggtt ggtgtctcag gaaagcctgt ccagctgagg 121 ccttccaaca tacagacaaa agatgtttct gttcaatgga agaagacaga acagggctca 181 cacagaaaaa ttgagatcct gaattggtat aatgatggtc ccagttggtc aaatgtatct 241 tttagtgata tctatggttt tgattatggg gattttgctc ttagtatcaa gtcagctaag 301 ctgcaagaca gtggtcacta cctgctggag atcaccaaca caggcggaaa agtgtgcaat 361 aagaacttcc agcttcttat acttgatcat gttgagaccc ctaacctgaa ggcccagtgg 421 aagccctgga ctaatgggac ttgtcaactg tttttgtcct gcttggtgac caaggatgac 481 aatgtgagct acgccttttg gtacagaggg agcactctga tctccaatca aaggaatagt 541 acccactggg agaaccagat tgacgccagc agcctgcaca catacacctg caacgttagc 601 aacagagcca gctgggcaaa ccacaccctg aacttcaccc atggctgtca aagtgtccct 661 tcgaatttca gatttctgcc ctttggggtg atcatcgtga ttctagttac attatttctc 721 ggggccatca tttgtttctg tgtgtggact aagaagagga agcagttaca gttcagccct 781 aaggaacctt tgacaatata tgaatatgtc aaggactcac gagccagcag ggatcaacaa 841 ggatgctcta gggcctctgg atctccctcg gctgtccagg aagatgggag gggacaaaga 901 gaattggaca ggcgtgtttc tgaggtgctg gagcagttgc cacagcagac tttccctgga 961 gatagaggca ccatgtactc tatgatacag tgcaagcctt ctgattccac atcacaagaa 1021 aaatgtacag tatattcagt agtccagcct tccaggaagt ctggatccaa gaagaggaac 1081 cagaactatt ccttaagttg taccgtgtac gaggaggttg gaaacccatg gctcaaagct 1141 cacaaccctg ccaggctgag ccgcagagag ctggagaact ttgatgtcta ctcctag
Nucleotide sequence in FASTA format (without gaps)
CD244*01
Amino acid sequence
1 MLGQAVLFTT FLLLRAHQGQ DCPDSSEEVV GVSGKPVQLR PSNIQTKDVS VQWKKTEQGS 61 HRKIEILNWY NDGPSWSNVS FSDIYGFDYG DFALSIKSAK LQDSGHYLLE ITNTGGKVCN 121 KNFQLLILDH VETPNLKAQW KPWTNGTCQL FLSCLVTKDD NVSYAFWYRG STLISNQRNS 181 THWENQIDAS SLHTYTCNVS NRASWANHTL NFTHGCQSVP SNFRFLPFGV IIVILVTLFL 241 GAIICFCVWT KKRKQLQFSP KEPLTIYEYV KDSRASRDQQ GCSRASGSPS AVQEDGRGQR 301 ELDRRVSEVL EQLPQQTFPG DRGTMYSMIQ CKPSDSTSQE KCTVYSVVQP SRKSGSKKRN 361 QNYSLSCTVY EEVGNPWLKA HNPARLSRRE LENFDVYS*
Amino acid sequence in FASTA format (without gap)
CD244*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT RepertoireChromosomal localization
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN on one layer, V-LIKE-DOMAIN on two layers, C-LIKE-DOMAIN on one layer, C-LIKE-DOMAIN on two layers
IMGT databases
- IMGT/3Dstructure-DB: 1z2k
External links
Nomenclature
- HGNC:
Genome databases
Sequence databases
- EMBL: L19057, AK137505, AF184208, AF234831, AF234830, AK171232, AK170167, AF082803, AK171544, AB196800, AB196801, AB196802, AB196803
- GenBank: L19057, AK137505, AF184208, AF234831, AF234830, AK171232, AK170167, AF082803, AK171544, AB196800, AB196801, AB196802, AB196803
- DDBJ: L19057, AK137505, AF184208, AF234831, AF234830, AK171232, AK170167, AF082803, AK171544, AB196800, AB196801, AB196802, AB196803
- Swiss-Prot: Q07763
- TrEMBL: Q9ESE5, Q9JIE1
- NCBI: NM_018729, NP_061199
Structure databases
- PDB: 1z2k
Created: 23/05/2007
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Philippe Cubry, Phani Vijay and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Philippe Cubry, Phani Vijay and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2024 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT