
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Mus musculus CTLA4
Citing IMGT RPI entry for CTLA4
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Mus musculus CTLA4
- IMGT gene definition: cytotoxic T-lymphocyte-associated protein 4
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1C;30.1cM
Gene exon/intron organization
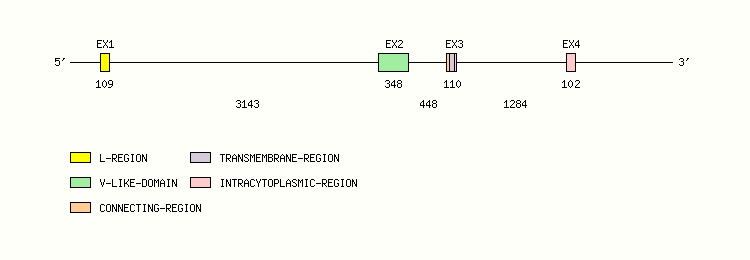
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 3
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | |||
|---|---|---|---|---|---|
| Clone | Exons | Accession numbers | Molecule type | ||
| CTLA4*01 | F | EX1-4 | AF142145 [1] | gDNA | |
| CTLA4*02 | F | EX1-4 | X05719 [2] | cDNA (1) | |
| CTLA4*03 | F | MGC:60618 | EX1-4 | BC052683 [3] | cDNA (2) |
IMGT reference sequences (in FASTA format) for the allele(s): CTLA4*01 to CTLA4*03
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | |||
|---|---|---|---|---|---|
| Clones | Exons | Accession numbers | Molecule type | ||
| CTLA4*01 | F | RP23-146J17 | EX1-4 | AL663047 | gDNA |
| MGC:51581 | EX1-4 | BC042741 | cDNA | ||
| EX1-4 | NM_009843 | ||||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| CTLA4*01 | AF142145 | 223 aa | 1 | |
| NM_009843 | NP_005205 | 223 aa | 1 | |
| CTLA4*02 | X05719 | P09793 | 223 aa | 1 |
| CTLA4*03 | BC052683 | 223 aa | 1 | |
IMGT notes:
- (1) In EX4 a87>t,T29>S.
- (2) EX2[D] a369>g, Q123>R, numbering according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN.
IMGT references:
PMID
PMID
PMID
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
CTLA4*01: AF142145(g)
Nucleotide sequence
1 atggcttgtc ttggactccg gaggtacaaa gctcaactgc agctgccttc taggacttgg 61 ccttttgtag ccctgctcac tcttcttttc atcccagtct tctctgaagc catacaggtg 121 acccaacctt cagtggtgtt ggctagcagc catggtgtcg ccagctttcc atgtgaatat 181 tcaccatcac acaacactga tgaggtccgg gtgactgtgc tgcggcagac aaatgaccaa 241 atgactgagg tctgtgccac gacattcaca gagaagaata cagtgggctt cctagattac 301 cccttctgca gtggtacctt taatgaaagc agagtgaacc tcaccatcca aggactgaga 361 gctgttgaca cgggactgta cctctgcaag gtggaactca tgtacccacc gccatacttt 421 gtgggcatgg gcaacgggac gcagatttat gtcattgatc cagaaccatg cccggattct 481 gacttcctcc tttggatcct tgtcgcagtt agcttggggt tgttttttta cagtttcctg 541 gtcactgctg tttctttgag caagatgcta aagaaaagaa gtcctcttac aacaggggtc 601 tatgtgaaaa tgcccccaac agagccagaa tgtgaaaagc aatttcagcc ttattttatt 661 cccatcaact ga
Nucleotide sequence in FASTA format (without gaps)
CTLA4*01
Amino acid sequence
1 MACLGLRRYK AQLQLPSRTW PFVALLTLLF IPVFSEAIQV TQPSVVLASS HGVASFPCEY 61 SPSHNTDEVR VTVLRQTNDQ MTEVCATTFT EKNTVGFLDY PFCSGTFNES RVNLTIQGLR 121 AVDTGLYLCK VELMYPPPYF VGMGNGTQIY VIDPEPCPDS DFLLWILVAV SLGLFFYSFL 181 VTAVSLSKML KKRSPLTTGV YVKMPPTEPE CEKQFQPYFI PIN*
Amino acid sequence in FASTA format (without gap)
CTLA4*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays: V-LIKE-DOMAINs
- IMGT Collier de perles: V-LIKE-DOMAIN on one layer, V-LIKE-DOMAIN on two layers
IMGT databases
- IMGT/3Dstructure-DB: 1dqt
External links
Genome databases
- Entrez Gene: 12477
- GENATLAS:
- GeneCards:
- GDB:
- OMIM:
Sequence databases
Created: 27/11/2006
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2024 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT