
IMGT Repertoire (RPI)
Other IgSF entries
- Homo sapiens: PDCD1
IMGT RPI entry from gene to protein for Mus musculus PDCD1
Citing IMGT RPI entry for PDCD1
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Mus musculus PDCD1
- IMGT gene definition: programmed cell death 1
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1D
Gene exon/intron organization
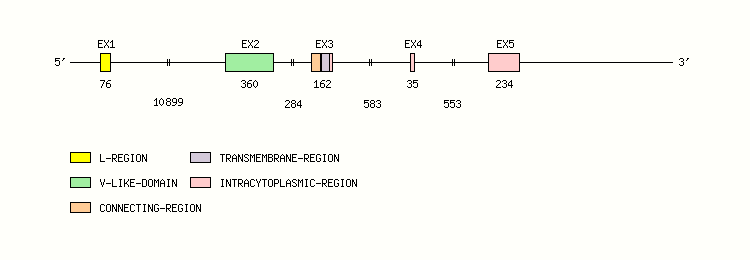
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 1
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| PDCD1*01 | F | EX1-5 | X67914 [1] | cDNA |
IMGT reference sequences (in FASTA format) for the allele(s): PDCD1*01
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | |||
|---|---|---|---|---|---|
| Clones | Exons | Accession numbers | Molecule type | ||
| PDCD1*01 | F | EX1-5 | AK039828 | cDNA | |
| MGC:155495 | EX1-5 | BC119179 | |||
| MGC:155839 | EX1-5 | BC120602 | |||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide Databases | Protein Databases | |||
| PDCD1*01 | X67914 | Q02242 | 288 aa | 1 |
| NM_008798 | NP_032824 | 288 aa | 1 | |
IMGT references:
- [1] Ishida.Y. et al, EMBO J. (11), 3887-3895 (1992). PMID:1396582
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
PDCD1*01: X67914(c)
Nucleotide sequence
1 atgtgggtcc ggcaggtacc ctggtcattc acttgggctg tgctgcagtt gagctggcaa 61 tcagggtggc ttctagaggt ccccaatggg ccctggaggt ccctcacctt ctacccagcc 121 tggctcacag tgtcagaggg agcaaatgcc accttcacct gcagcttgtc caactggtcg 181 gaggatctta tgctgaactg gaaccgcctg agtcccagca accagactga aaaacaggcc 241 gccttctgta atggtttgag ccaacccgtc caggatgccc gcttccagat catacagctg 301 cccaacaggc atgacttcca catgaacatc cttgacacac ggcgcaatga cagtggcatc 361 tacctctgtg gggccatctc cctgcacccc aaggcaaaaa tcgaggagag ccctggagca 421 gagctcgtgg taacagagag aatcctggag acctcaacaa gatatcccag cccctcgccc 481 aaaccagaag gccggtttca aggcatggtc attggtatca tgagtgccct agtgggtatc 541 cctgtattgc tgctgctggc ctgggcccta gctgtcttct gctcaacaag tatgtcagag 601 gccagaggag ctggaagcaa ggacgacact ctgaaggagg agccttcagc agcacctgtc 661 cctagtgtgg cctatgagga gctggacttc cagggacgag agaagacacc agagctccct 721 accgcctgtg tgcacacaga atatgccacc attgtcttca ctgaagggct gggtgcctcg 781 gccatgggac gtaggggctc agctgatggc ctgcagggtc ctcggcctcc aagacatgag 841 gatggacatt gttcttggcc tctttga
Nucleotide sequence in FASTA format (without gaps)
PDCD1*01
Amino acid sequence
1 MWVRQVPWSF TWAVLQLSWQ SGWLLEVPNG PWRSLTFYPA WLTVSEGANA TFTCSLSNWS 61 EDLMLNWNRL SPSNQTEKQA AFCNGLSQPV QDARFQIIQL PNRHDFHMNI LDTRRNDSGI 121 YLCGAISLHP KAKIEESPGA ELVVTERILE TSTRYPSPSP KPEGRFQGMV IGIMSALVGI 181 PVLLLLAWAL AVFCSTSMSE ARGAGSKDDT LKEEPSAAPV PSVAYEELDF QGREKTPELP 241 TACVHTEYAT IVFTEGLGAS AMGRRGSADG LQGPRPPRHE DGHCSWPL*
Amino acid sequence in FASTA format (without gap)
PDCD1*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN on one layer, V-LIKE-DOMAIN on two layers
External links
Genome databases
- Entrez Gene: 29851
- GENATLAS: ICOS
- GeneCards: GC02P204626
- GDB: 10450295
- OMIM: 604558
Sequence databases
- EMBL: AF411058, AF411059, AC103880, AF488346, AF488347, AJ535718, AB023135, AJ277832, BC028210, BC028006
- GenBank: AF411058, AF411059, AC103880, AF488346, AF488347, AJ535718, AB023135, AJ277832, BC028210, BC028006
- DDBJ: AF411058, AF411059, AC103880, AF488346, AF488347, AJ535718, AB023135, AJ277832, BC028210, BC028006
- Swiss-Prot: Q9Y6W8
- TrEMBL:
- NCBI: NM_012092, NP_036224
Structure database
- PDB:
Created: 27/11/2006
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2024 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT