
IMGT Repertoire (RPI)
Other B7 Family entries
IMGT RPI entry from gene to protein for Homo sapiens B7DC
Citing IMGT RPI entry for B7DC
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens B7DC
- IMGT gene definition: programmed cell death 1 ligand 2
Chromosomal localization
- Chromosome: 9
- Chromosomal localization: 9p24.2
Gene exon/intron organization
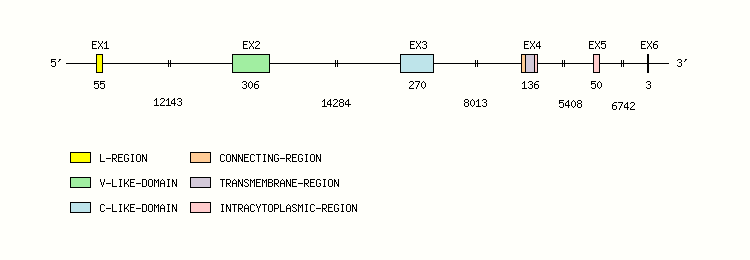
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 3
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| B7DC*01 | F | EX1-6 | AL162253[1] | gDNA |
| B7DC*02 | F | EX1-6 | AF329193 | cDNA (1) |
| B7DC*03 | F | EX1-6 | EF444806 | cDNA (2) |
IMGT reference sequences (in FASTA format) for the allele(s): B7DC*01 to B7DC*03
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | Clone names | IMGT reference sequences | |||
|---|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||||
| B7DC*01 | F | EX1-6 | AF344424 | cDNA | ||
| EX1-6 | AY254343 | |||||
| MGC:103803 | EX1-6 | BC074766 | ||||
| MGC:142240 | EX1-6 | BC113680 | ||||
| EX1-6 | NM_025239 | |||||
| EX1-6 | DQ336699 | cDNA partial EX1 | ||||
| EX1-2, 4-6 | AY271901 | cDNA (3) splicing B | ||||
| EX1-2, 4-6 | AY271902 | cDNA, partial (4) splicing C | ||||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| B7DC*01 | AL162253 | Tr:Q9BQ51 | 273 aa | 1 |
| B7DC*02 | AF329193 | 273 aa | 1 | |
| NM_025239 | NP_079515 | 273 aa | 1 | |
| AY271901 | 183 aa | 2 | ||
| AY271902 | 182 aa | 3 | ||
| B7DC*03 | EF444806 | 273 aa | 1 | |
IMGT notes:
- (1) In EX4 t55>c; F19>S.
- (2) In EX4 t55>c; F19>S and a99>g; R34>G.
- (3) Splicing B (183 aa) has no EX3. New amino acid (S>G) at position 1 in EX4.
- (4) Splicing C (182 aa), partial. No EX3. Utlize an alternative 5'acceptor splice site 5 nt beyond the normal splice site leading to frameshift.
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
B7DC*01: AL162253(g)
Nucleotide sequence
1 atgatcttcc tcctgctaat gttgagcctg gaattgcagc ttcaccagat agcagcttta 61 ttcacagtga cagtccctaa ggaactgtac ataatagagc atggcagcaa tgtgaccctg 121 gaatgcaact ttgacactgg aagtcatgtg aaccttggag caataacagc cagtttgcaa 181 aaggtggaaa atgatacatc cccacaccgt gaaagagcca ctttgctgga ggagcagctg 241 cccctaggga aggcctcgtt ccacatacct caagtccaag tgagggacga aggacagtac 301 caatgcataa tcatctatgg ggtcgcctgg gactacaagt acctgactct gaaagtcaaa 361 gcttcctaca ggaaaataaa cactcacatc ctaaaggttc cagaaacaga tgaggtagag 421 ctcacctgcc aggctacagg ttatcctctg gcagaagtat cctggccaaa cgtcagcgtt 481 cctgccaaca ccagccactc caggacccct gaaggcctct accaggtcac cagtgttctg 541 cgcctaaagc caccccctgg cagaaacttc agctgtgtgt tctggaatac tcacgtgagg 601 gaacttactt tggccagcat tgaccttcaa agtcagatgg aacccaggac ccatccaact 661 tggctgcttc acattttcat ccccttctgc atcattgctt tcattttcat agccacagtg 721 atagccctaa gaaaacaact ctgtcaaaag ctgtattctt caaaagacac aacaaaaaga 781 cctgtcacca caacaaagag ggaagtgaac agtgctatct ga
Nucleotide sequence in FASTA format (without gaps)
B7DC*01
Amino acid sequence
1 MIFLLLMLSL ELQLHQIAAL FTVTVPKELY IIEHGSNVTL ECNFDTGSHV NLGAITASLQ 61 KVENDTSPHR ERATLLEEQL PLGKASFHIP QVQVRDEGQY QCIIIYGVAW DYKYLTLKVK 121 ASYRKINTHI LKVPETDEVE LTCQATGYPL AEVSWPNVSV PANTSHSRTP EGLYQVTSVL 181 RLKPPPGRNF SCVFWNTHVR ELTLASIDLQ SQMEPRTHPT WLLHIFIPFC IIAFIFIATV 241 IALRKQLCQK LYSSKDTTKR PVTTTKREVN SAI*
Amino acid sequence in FASTA format (without gap)
B7DC*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN on one layer, V-LIKE-DOMAIN on two layers, C-LIKE-DOMAIN on one layer, C-LIKE-DOMAIN on two layers
External links
Nomenclature
- HGNC: 18731
Genome databases
Sequence database
- EMBL: AL162253, AF329193, AF344424, AY254343, BC074766, BC113680, DQ336699, AY271901, AY271902, EF444806
- GenBank: AL162253, AF329193, AF344424, AY254343, BC074766, BC113680, DQ336699, AY271901, AY271902, EF444806
- DDBJ: AL162253, AF329193, AF344424, AY254343, BC074766, BC113680, DQ336699, AY271901, AY271902, EF444806
- Swiss-Prot:
- TrEMBL: Q2LC89, Q9BQ51
- NCBI: NM_025239, NP_079515
Structure database
- PDB:
Created: 23/05/2007
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2024 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT