
IMGT Repertoire (RPI)
Other B7 Family entries
IMGT RPI entry from gene to protein for Mus musculus B7H2
Citing IMGT RPI entry for B7H2
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Mus musculus B7H2
- IMGT gene definition: inducible T-cell co-stimulator ligand
Chromosomal localization
- Chromosome: 10
- Chromosomal localization: 10 C1
Gene exon/intron organization
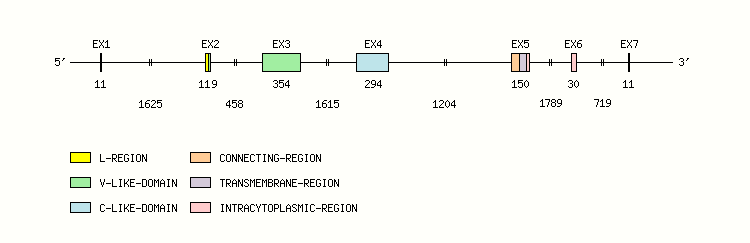
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 2
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| B7H2*01 | F | EX1-7 | AF394451[1] | cDNA |
| B7H2*02 | F | EX1-6, 8 | AF199027 [2] | cDNA (1) splicing B |
IMGT reference sequences (in FASTA format) for the allele(s): B7H2*01 to B7H2*02
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| B7H2*02 | F | EX1-6,8 | AF216747 | cDNA splicing B |
| BC029227 | cDNA splicing B | |||
| AK041421 | cDNA splicing B | |||
| AK136074 | cDNA splicing B | |||
| NM_015790 | cDNA splicing B | |||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| B7H2*01 | AF394451 | 347 aa | 1 | |
| NM_015790 | NP_056605 | 322 aa | 2 | |
IMGT notes:
- (1) Splicing B (322 aa). No EX7. In EX4 a48>g, a295>g; H99>R, positions according to the IMGT unique numbering for the C-DOMAIN and C-LIKE-DOMAIN.
IMGT references:
- [1] Ling V. et al. The Journal of Immunology, 166, 7300-7308(2001). PMID:11390480
- [2] Ling V. et al. The Journal of Immunology, 164, 1653-1657(2000). PMID:10657606
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
B7H2*01: AF199028(c)
Nucleotide sequence
1 atgcagctaa agtgtccctg ttttgtgtcc ttgggaacca ggcagcctgt ttggaagaag 61 ctccatgttt ctagcgggtt cttttctggt cttggtctgt tcttgctgct gttgagcagc 121 ctctgtgctg cctctgcaga gactgaagtc ggtgcaatgg tgggcagcaa tgtggtgctc 181 agctgcattg acccccacag acgccatttc aacttgagtg gtctgtatgt ctattggcaa 241 atcgaaaacc cagaagtttc ggtgacttac tacctgcctt acaagtctcc agggatcaat 301 gtggacagtt cctacaagaa caggggccat ctgtccctgg actccatgaa gcagggtaac 361 ttctctctgt acctgaagaa tgtcacccct caggataccc aggagttcac atgccgggta 421 tttatgaata cagccacaga gttagtcaag atcttggaag aggtggtcag gctgcgtgtg 481 gcagcaaact tcagtacacc tgtcatcagc acctctgata gctccaaccc aggccaggaa 541 cgtacctaca cctgcatgtc caagaatggc tacccagagc ccaacctgta ttggatcaac 601 acaacggaca atagcctaat agacacggct ctgcagaata acactgtcta cttgaacaag 661 ttgggcctgt atgatgtaat cagcacatta aggctccctt ggacatctca tggggatgtt 721 ctgtgctgcg tagagaatgt ggctctccac cagaacatca ctagcattag ccaggcagaa 781 agtttcactg gaaataacac aaagaaccca caggaaaccc acaataatga gttaaaagtc 841 cttgtccccg tccttgctgt actggcggca gcggcattcg tttccttcat catatacaga 901 cgcacgcgtc cccaccgaag ctatacagga cccaagactg tacagcttga acttacagac 961 acttgggctc cggtccccta ccaggactat ttgattccaa gatatttgat gtctccatgc 1021 ctcaaaacac gtggtttacc ataa
Nucleotide sequence in FASTA format (without gaps)
B7H2*01
Amino acid sequence
1 MQLKCPCFVS LGTRQPVWKK LHVSSGFFSG LGLFLLLLSS LCAASAETEV GAMVGSNVVL 61 SCIDPHRRHF NLSGLYVYWQ IENPEVSVTY YLPYKSPGIN VDSSYKNRGH LSLDSMKQGN 121 FSLYLKNVTP QDTQEFTCRV FMNTATELVK ILEEVVRLRV AANFSTPVIS TSDSSNPGQE 181 RTYTCMSKNG YPEPNLYWIN TTDNSLIDTA LQNNTVYLNK LGLYDVISTL RLPWTSHGDV 241 LCCVENVALH QNITSISQAE SFTGNNTKNP QETHNNELKV LVPVLAVLAA AAFVSFIIYR 301 RTRPHRSYTG PKTVQLELTD TWAPVPYQDY LIPRYLMSPC LKTRGLP*
Amino acid sequence in FASTA format (without gap)
B7H2*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN on one layer, V-LIKE-DOMAIN on two layers, C-LIKE-DOMAIN on one layer, C-LIKE-DOMAIN on two layers
External links
Nomenclature
- HGNC:
Genome databases
Sequence database
- EMBL: AF394451, AX100593, AX100591, AF216747, BC029227, AF199027, AK136074, AK041421, AC041421
- GenBank: AF394451, AX100593, AX100591, AF216747, BC029227, AF199027, AK136074, AK041421, AC041421
- DDBJ: AF394451, AX100593, AX100591, AF216747, BC029227, AF199027, AK136074, AK041421, AC041421
- Swiss-Prot:
- TrEMBL: Q3UWV7, Q544C7, Q571G9, Q9JHJ8
- NCBI: NM_015790, NP_056605
Structure database
- PDB:
Created: 23/05/2007
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2024 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT